
티스토리 뷰
더보기
📝 목차
1. 도입
2. 문제: 쿼드 트리 뒤집기
3. 문제: 울타리 잘라내기
4. 문제: 팬미팅
1. 도입
분할 정복은 가장 유명한 알고리즘 디자인 패러다임으로, 각개 격파라는 말로 설명할 수 있다.

✏️ 분할정복과 일반적인 재귀호출과의 차이점
- 재귀호출: 항상 문제를 한 조각과 나머지로 쪼갠다.
- 분할 정복: 항상 문제를 절반씩으로 나눈다.
✏️ 분할정복의 세가지 구성 요소
- 문제를 더 작은 문제로 분할하는 과정(divide)
- 각 문제에 대해 구한 답을 원래 문제에 대한 답으로 병합하는 과정(merge)
- 더이상 답을 분할하지 않고 곧장 풀 수 있는 매우 작은 문제(base case)
✏️ 분할 정복의 필요조건
- 문제를 둘 이상의 부분 문제로 나누는 자연스러운 방법이 있어야 한다.
- 부분 문제의 답을 조합해 원래 문제의 답을 계산하는 효율적인 방법이 있어야 한다.
📍 예제: 수열의 빠른 합과 행렬의 빠른 제곱
재귀호출을 사용하는 recursiveSum()함수와 똑같은 일을 하는 분할 정복을 이용한 fastSum()함수를 만들어보자.
1부터 n까지의 합을 n개의 조각으로 나눈 뒤, 이들을 반으로 뚝 잘라 n/2개의 조각들로 만들어진 부분 문제 두 개를 만든다.
(편의상 n은 짝수로 가정)
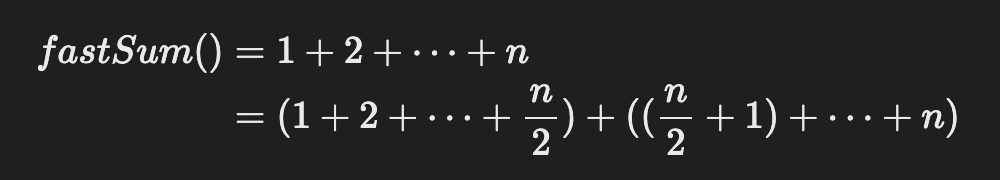
- 첫 번째 부분 문제는 fastSum(n/2)로 나타낼 수 있지만, 두 번째 부분 문제는 그렇지 않다.
- 문제를 재귀적으로 풀기 위해 각 부분 문제를 '1부터 n까지의 합' 꼴로 표현할 수 있어야 하는데,
- 위의 분할에서 두 번째 조각은 'a부터 b까지의 합' 형태를 가지기 때문이다.
다음과 같이 두 번째 부분 문제를 fastSum(x)를 포함하는 형태로 바꿔써야 한다.

위와 같은 아이디어로 코드를 구현한 것이다.
이 함수에서 홀수와 짝수인 경우 어떻게 처리하는지 확인해보자.
// 코드 7.1 1부터 n까지의 합을 구하는 분할 정복 알고리즘
// 필수 조건: n은 자연수
// 1부터 n까지의 합을 반환한다
func fastSum(_ n: Int) -> Int {
// 기저 사례
if n == 1 {return 1}
if(n % 2 == 1)return fastSum(n - 1) + n
return 2 * fastSum(n/2) + (n/2) * (n/2)
}
시간 복잡도 분석
fastSum()은 recursiveSum()과의 차이는?
fastSum()은 recursiveSum()보다 함수 호출이 절반으로 줄어든다.

위는 fastSum(11)을 실행할 때 재귀 호출의 입력이 어떻게 변화하는지를 이진수 표현으로 보여준다.
- fastSum()의 총 호출 횟수는 n의 이진수 표현의 자릿수 + 첫 자리를 제외하고 나타나는 1의 개수가 된다.
- 두 값의 상한은 모두 lg(n)이므로 알고리즘의 실행 시간은 O(lg(n))이 된다.
행렬의 거듭제곱
n*n 크기의 행렬 A가 주어질 때, A의 거듭제곱 A^m은 A를 연속해서 m번 곱한 것이다.
만약 m의 크기가 매우 크다면 시간이 오래걸리게 된다.
- 행렬의 곱셈은 O(n^3)의 시간이 들어 m-1번의 곱셈을 통해 A^m을 구하려면
- 모두 O(n^3*m)의 시간이 걸린다.
✏️ 거듭제곱 구하기 위한 분할 정복 알고리즘
- A^m = A^m/2 × A^m/2
// 코드 7.2 행렬의 거듭제곱을 구하는 분할 정복 알고리즘
// 정방행렬을 표현하는 SquareMatrix 클래스
class SquareMatrix {
// 기본 생성자
init() {
// 행렬 생성과 초기화 코드
}
// 행렬의 크기를 반환하는 함수
func size() -> Int {
// 행렬 크기 반환 코드
return 0 // 실제 행렬 크기로 변경해야 함
}
}
// n*n 크기의 항등 행렬(identity matrix)을 반환하는 함수
func identity(_ n: Int) -> SquareMatrix {
}
// A^m을 반환하는 함수
func pow(_ A: SquareMatrix, _ m: Int) -> SquareMatrix {
// 기저 사례: A^0 = I
if m == 0 {
return identity(A.size())
}
if m % 2 > 0 {
return pow(A, m - 1) * A
}
let half = pow(A, m / 2)
// A^m = (A^(m/2)) * (A^(m/2))
return half * half
}
나누어 떨어지지 않을 때의 분할과 시간 복잡도
문제의 크기가 매번 절반에 가깝게 줄어들면 기저 사례에 도달하기까지 걸리는 분할 횟수가 줄어들어
분할 정복 알고리즘은 가능한 한 절반에 가깝게 절반에 나누고자 한다.
m이 홀수일 때, A^m = A * A^m-1로 나누는 것이 A^7 = A^3 * A^4로 나누는 것보다 효율이 더 좋을 수 있다.
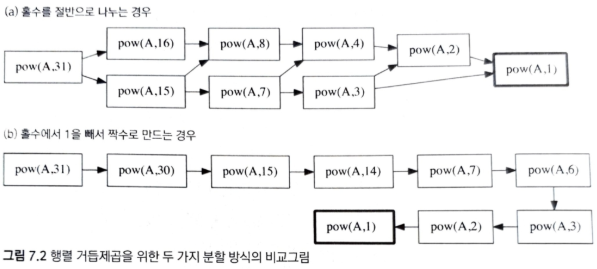
위의 예시는 어떻게 분할하느냐에 따라 시간 복잡도의 차이가 커진다는 것을 보여준다.
- 절반으로 나누는 알고리즘이 큰 효율 저하를 일으킨다.
- A^m을 찾기 위해 계산해야 할 부분 문제들이 늘어나기 때문이다.
📍 예제: 병합 정렬과 퀵 정렬
두 알고리즘 모두 분할 정복 패러다임을 사용한 알고리즘이다.
같은 아이디어로 정렬을 수행하지만 "시간이 많이 걸리는 작업을 분할 단계에서 하느냐", "병합 단계에서 하느냐"가 다르다.
1️⃣ 병합 정렬
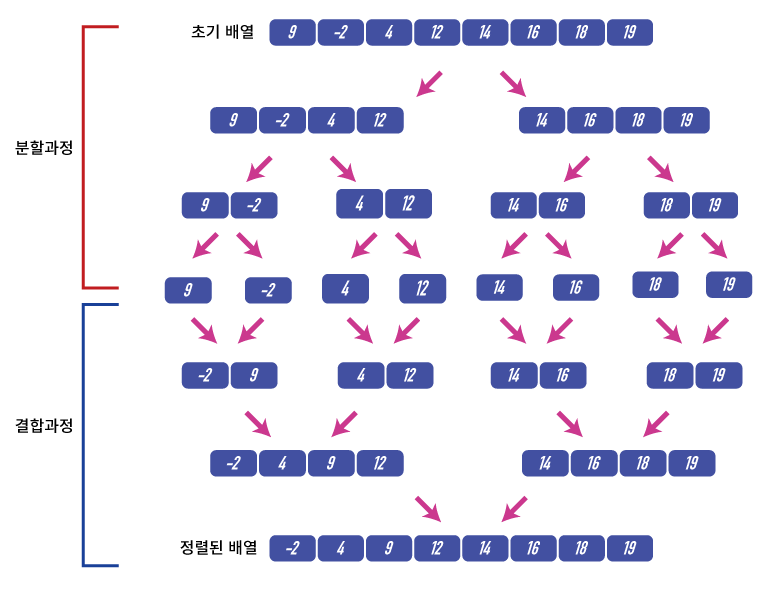
- 주어진 수열을 가운데에서 쪼개 비슷한 크기의 수열 두 개로 만든 뒤 재귀 호출을 이용해 각각 정렬한다.
- 정렬된 배열을 하나로 합침으로써 정렬된 전체 수열을 얻는다.
- 분할 과정은 O(1)만에 수행가능하지만, 병합 과정에서 O(n)의 시간이 걸린다.
2️⃣ 퀵 정렬
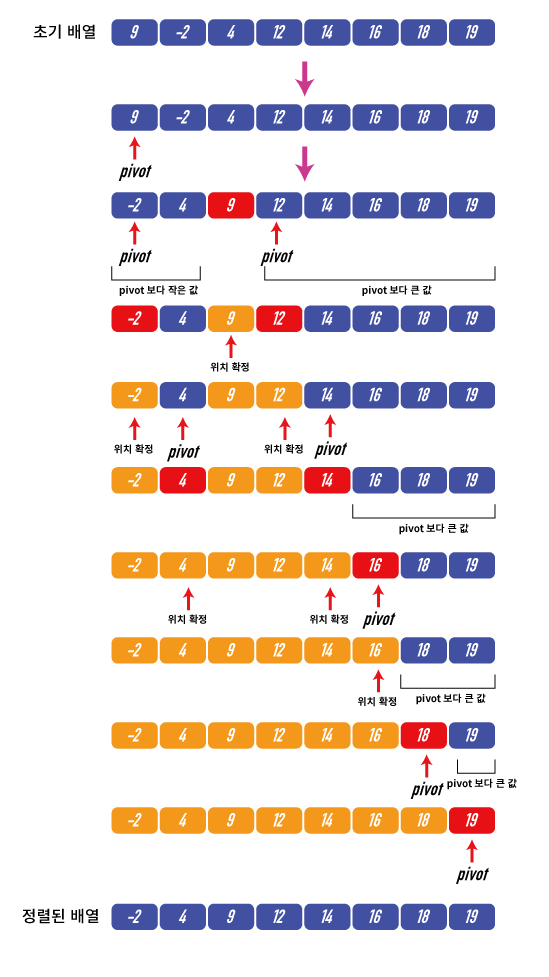
- 병합과정이 필요 없도록 한쪽의 배열에 포함된 수가 다른 쪽 배열의 수보다 항상 작도록 배열을 분할한다.
- '파티션'이라는 단계를 도입
- 배열에 있는 수 중 임의의 기준 수(pivot)를 지정한 후 기준보다 작거나 같은 숫자를 왼쪽, 더 큰 숫자를 오른쪽으로 보내는 과정
- 분할 과정은 O(n)의 시간이 걸리며 선택한 기준에 따라 비효율적인 분할을 불러올 수 있지만, 병합 과정이 필요없다.
시간 복잡도 분석
1️⃣ 병합 정렬
- 병합에 필요한 과정은 O(n), 분할 과정에 필요한 과정은 O(lg(n))으로 항상 일정
- 문제의 크기는 항상 거의 절반으로 나누어지기 때문에 필요한 단계의 수는 O(lg(n))으로 시간 복잡도는 O(nlg(n))이 된다.
2️⃣ 퀵 정렬
- 대부분의 시간을 차지하는 것은 주어진 문제를 두 개의 부분 문제로 나누는 파티션 과정이다.
- 파티션은 주어진 수열의 길이에 비례하여 시간이 걸리므로, 병합 정렬에서의 병합 과정과 다를 것이 없다.
- 부분 문제가 절반에 가깝게 나눠질 때 평균적으로 퀵 정렬의 시간 복잡도는 O(nlg(n))이 된다.
- 최악의 경우(기준으로 택한 원소가 최소 원소나 최대 원소인 경우)는 시간복잡도가 O(n^2)이된다.
📍 예제: 카라츠바의 빠른 곱셈 알고리즘
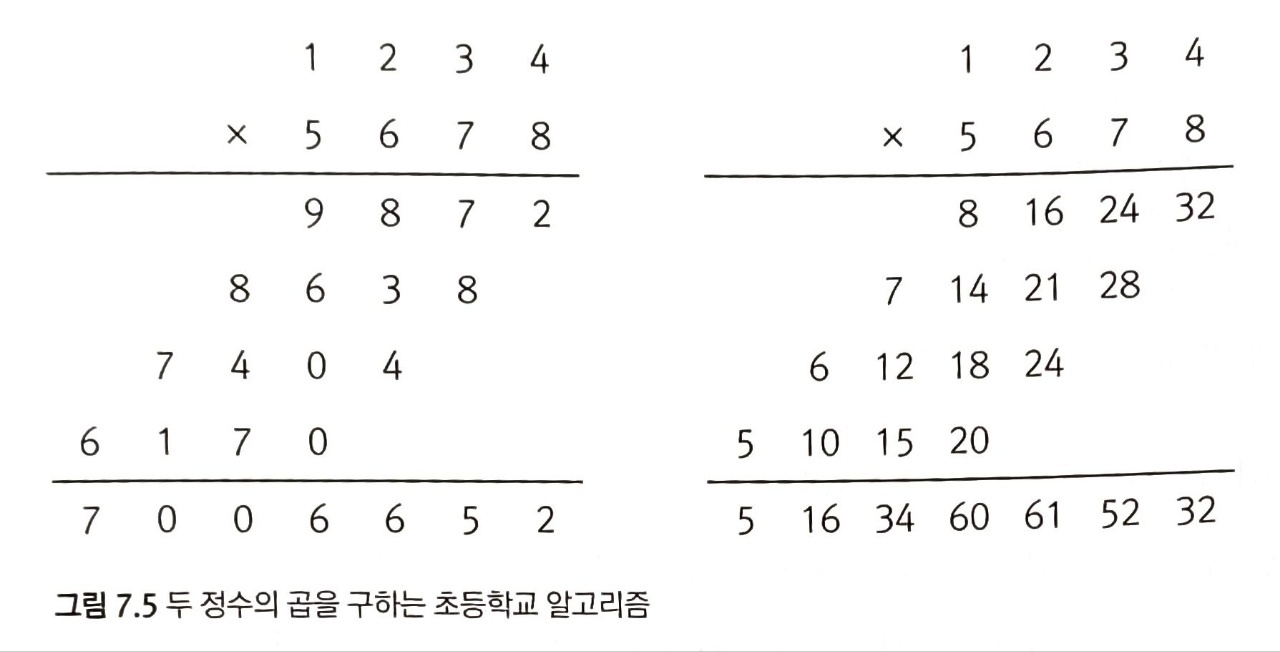
카라츠바 빠른 곱셈 알고리즘: 두 개의 정수를 곱하는 알고리즘, 수백 자리나 수만 자리의 큰 숫자를 다룸
두 정수의 곱을 구하는 과정
// 코드 7.3 두 큰 수를 곱하는 O(n^2)시간 알고리즘
// num 배열의 자릿수 올림을 처리한다
func normalize(_ num: inout [Int]) {
num.append(0)
// 자릿수 올림을 처리한다
for i in 0..<num.count {
if num[i] < 0 {
let borrow = (abs(num[i]) + 9) / 10
num[i + 1] -= borrow
num[i] += borrow * 10
} else {
num[i + 1] += num[i] / 10
num[i] %= 10
}
}
while num.count > 1 && num.last == 0 {
num.removeLast()
}
}
// 두 긴 자연수의 곱을 반환한다
// 각 배열에는 각 수의 자릿수가 1의 자리에서부터 시작해 저장되어 있다
// 예 : multiply([3, 2, 1], [6, 5, 4]) = 123 * 456 = 56088 = [8, 8, 0, 6, 5]
func multiply(_ a: [Int], _ b: [Int]) -> [Int] {
var c = [Int](repeating: 0, count: a.count + b.count + 1)
for i in 0..<a.count {
for j in 0..<b.count {
c[i + j] += a[i] * b[j]
}
}
normalize(&c)
return c
}
- 배열을 뒤집으면 입출력할 때는 불편하지만, A[i]에 주어진 자릿수의 크기를 10^i로 쉽게 구할 수 있다.
- 자릿수 올림을 처리하는 normalize()에서 자릿수가 음수인 경우도 처리한다.
- multiply()에서 덧셈밖에 하지 않아, 자릿수가 음수가 될 일이 없다.
- 두 정수의 길이가 모두 n인 경우 시간 복잡도는 O(n^2)이다. (n번 실행되는 반복문이 이중이기 때문)
카라츠바 알고리즘
// 코드 7.4 카라츠바의 빠른 정수 곱셈 알고리즘
// a += b * (10^k)를 구현한다
func addTo(_ a: inout [Int], _ b: [Int], _ k: Int) {
let length = b.count
a.append(contentsOf: repeatElement(0, count: max(a.count + 1, b.count + k)))
for i in 0..<length {
a[i + k] += b[i]
}
normalize(&a) // 정규화
}
// a -= b; 를 구현한다. a >= b를 가정한다
func subFrom(_ a: inout [Int], _ b: [Int]) {
let length = b.count
a.append(contentsOf: repeatElement(0, count: max(a.count + 1, b.count) + 1))
for i in 0..<length {
a[i] -= b[i]
}
normalize(&a) // normalize()가 음수를 처리하는 이유
}
// 두 긴 정수의 곱을 반환한다
func karatsuba(_ a: [Int], _ b: [Int]) -> [Int] {
let an = a.count, bn = b.count
// a가 b보다 짧을 경우 둘을 바꾼다
if an < bn { return karatsuba(b, a) }
// 기저 사례: a나 b가 비어 있는 경우
if an == 0 || bn == 0 { return [] }
// 기저 사례: a가 비교적 짧은 경우 O(n^2) 곱셈으로 변경한다
if an <= 50 { return multiply(a, b) }
let half = an / 2
// a와 b를 밑에서 half 자리와 나머지로 분리한다
let a0 = Array(a[..<half])
let a1 = Array(a[half...])
let b0 = Array(b[..<min(b.count, half)])
let b1 = Array(b[min(b.count, half)...])
// z2 = a1 * b1
let z2 = karatsuba(a1, b1)
// z0 = a0 * b0
let z0 = karatsuba(a0, b0)
// a0 = a0 + a1; b0 = b0 + b1
addTo(&a0, a1, 0)
addTo(&b0, b1, 0)
// z1 = (a0 * b0) - z0 - z2;
var z1 = karatsuba(a0, b0)
subFrom(&z1, z0)
subFrom(&z1, z2)
// ret = z0 + z1 * 10^half + z2 * 10^(half*2)
var ret: [Int] = []
addTo(&ret, z0, 0)
addTo(&ret, z1, half)
addTo(&ret, z2, half + half)
return ret
}
1. 두 수를 각각 절반으로 쪼갠다.
만약 a와 b가 각각 256자리 수라면 a1,b1은 첫 128자리, a0과 b0은 그 다음 128자리를 저장한다.
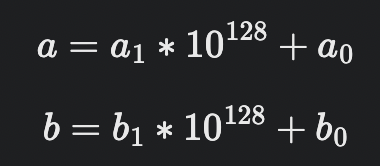
2. a*b를 네 개의 조각을 이용해 표현

큰 정수 두개를 한번에 곱하는 대신, 절반 크기로 나눈 작은 조각을 네번 곱한다.
- 덧셈과 시프트 연산에 걸리는 시간: O(n)
- n/2길이 조각들의 곱셈 네 번: 4 * T(n/2)
길이 n인 두 정수를 곱하는데 드는 시간 = O(n) + 4 * T(n/2)
전체 시간 복잡도 => O(n^2)
3. 세 번의 곱셈으로 계산
다음과 같이 a*b로 표현했을 때 네 번 대신 세 번의 곱셈으로 이 값을 계산할 수 있다.
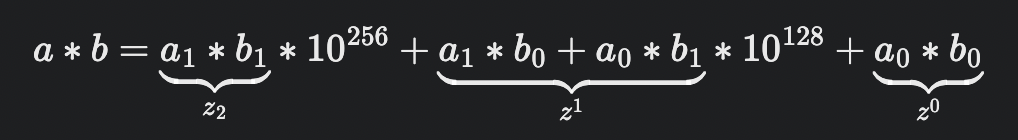
조각들의 곱을 각각 z2, z1, z0이라고 하자.
우선 z0와 z2를 각각 한 번의 곱셈으로 구한다.
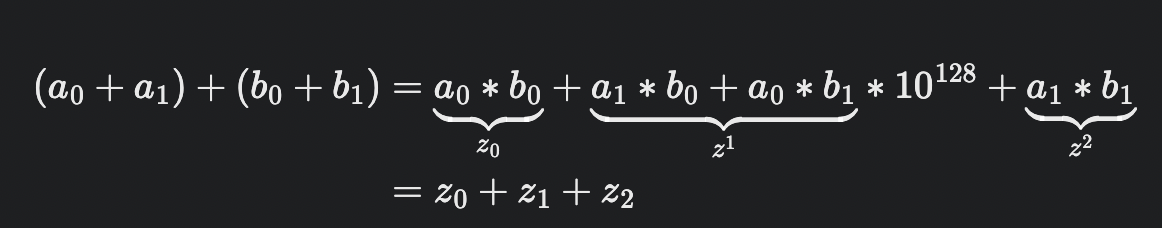
z0과 z2를 빼서 z1을 구할 수 있다. 다음과 같은 코드 조각을 이용할 수 있다.
z2 = a1 * b1;
z0 = a0 * b0;
z1 = (a0 + a1) * (b0 + b1) - z0 - z2;
세 결과를 다시 적절히 조합해 원래 두 수의 답을 구할 수 있다.
🔎 시간 복잡도 분석
카라츠바 알고리즘은 두 개의 입력을 절반씩으로 쪼갠 뒤, 세 번 재귀 호출을 하기 때문에 지금까지의 예제와는 다르게 분석해야 한다.
- 카라츠바 알고리즘의 수행시간을 병합 단계와 기저 사례의 두 부분으로 나누자.
- 코드 7.4 구현에서 병합 단계의 수행시간은 addTo()와 subFrom()의 수행 시간에 지배,
- 기저 사례의 처리시간은 multiply()의 수행시간에 지배된다.
- 기저 사례를 처리하는 데 드는 총 시간을 알아보자.
- 자릿수 n이 2의 거듭제곱 2^k라고 했을 때 재귀 호출의 깊이는 k이다.
- 한번 쪼갤 때마다 해야 할 곱셈의 수가 세 배씩 늘어나기 때문에 마지막 단계에는 3^k의 부분 문제가 있다.
- 마지막 단계는 두 수 모두 한자리기 때문에 곱셈 한번으로 해결할 수 있다.
- 따라서 곱셈의 수는 O(3^k)가 된다.
- O(3^k) = (3^(lgn)) = O (n^(lg3))
- 병합 단계에 드는 시간의 총 합을 구해보자.
- addTo()와 subFrom()은 숫자의 길이에 비례하는 시간만이 걸리도록 구현할 수 있다.
- 따라서 각 단계에 해당하는 숫자의 길이를 모두 더하면 병합 단계에 드는 시간 계산할 수 있다.
- 단계가 내려갈 때마다 숫자의 길이 절반, 부분 문제의 개수는 세 배 증가
- i번째 단계에서 필요한 연산 수는 (3/2)^i * n이 된다.
- 시간 복잡도는 곱셈이 지배하며, 최종 시간 복잡도는 O(n^lg3)이다.
※ 입력의 크기가 작을 경우 O(N^2)알고리즘보다 느린 경우가 많다.
2. 문제: 쿼드 트리 뒤집기
문제
algospot.com :: QUADTREE
쿼드 트리 뒤집기 문제 정보 문제 대량의 좌표 데이터를 메모리 안에 압축해 저장하기 위해 사용하는 여러 기법 중 쿼드 트리(quad tree)란 것이 있습니다. 주어진 공간을 항상 4개로 분할해 재귀적
algospot.com
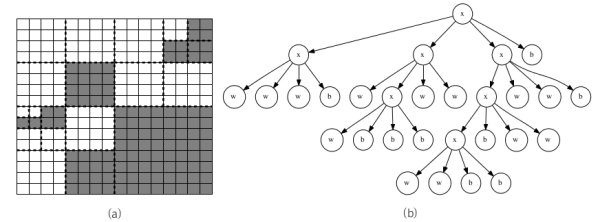
- 쿼드 트리: 대량의 좌표 데이터를 메모리 안헤 압축해 저장하기 위해 사용하는 여러 기법 중 하나
- 주어진 공간을 항상 4개로 분할해 재귀적으로 표현
풀이
1️⃣ 접근 방법
문제를 푸는 가장 무식한 방법으로 주어진 그림의 쿼드 트리 압축을 풀어 실제 이미지를 얻고 상하 반전한 뒤 다시 쿼드 트리 압축하는 것이 있다. 하지만 원본 그림의 크기 제한 때문에 무식하게는 못 푼다.
이런 경우, 문제 접근 방법 두 가지
- 큰 입력에 대해서도 동작하는 효율적인 알고리즘 처음부터 새로 만들기
- 작은 입력에 대해서만 동작하는 단순한 알고리즘으로부터 시작해서 최적화해 나가기
우선 그림의 크기에 신경쓰지 않고 더 쉬운 단순한 알고리즘부터 시작하여 최적화해 나가보자.
2️⃣ 쿼드 트리 압축 풀기
쿼드 트리가 재귀적으로 정의되어 있어 압축하거나 해제하는 과정은 재귀 호출로 구현하는 것이 가장 자연스럽다.
문자열 s의 압축을 해제해 N*N 크기의 배열을 저장하는 함수 decompress()를 구현해보자.
var decompressed = Array(repeating: Array(repeating: Character(" "), count: MAX_SIZE), count: MAX_SIZE)
func decompress(_ it: inout String.Iterator, _ y: Int, _ x: Int, _ size: Int) {}
- 기저 사례는 s의 첫 글자가 w나 b인 경우, 이때는 배열 전체에 해당 색을 색칠하고 종료한다.
- 첫 글자가 x라면 decompress()는 s의 나머지 부분을 넷으로 쪼개 재귀 호출한다.
3️⃣ 압축 문자열 분할하기
각 부분의 길이가 일정하지 않아 s의 나머지 부분을 넷으로 쪼개기가 까다롭다.
이를 해결하기 위한 두 가지 방법,
- 주어진 위치에서 시작하는 압축 결과의 길이를 반환하는 함수 getChunkLength()를 만든다.
- getChunkLength()를 재귀 호출로 작성하는 것은 어렵지 않지만, 비슷한 일을 하는 두 개의 함수를 각각 작성하는 점이 별로다.
- s를 미리 쪼개는 것이 아니라 decompress()함수에서 '필요한 만큼 가져다 쓰도록' 하는 것이다.
- decompress()함수에 s를 통째로 전달하는 것이 아니라, s의 한 글자를 가리키는 포인터를 전달한다.
아래의 코드는 2의 방법을 이용해 구현한 코드이다.
// 코드 7.5 쿼드 트리 압축을 해제하는 재귀 호출 알고리즘
var decompressed = Array(repeating: Array(repeating: Character(" "), count: MAX_SIZE), count: MAX_SIZE)
func decompress(_ it: inout String.Iterator, _ y: Int, _ x: Int, _ size: Int) {
// 한 글자를 검사할 때마다 반복자를 한 칸 앞으로 옮긴다
guard let head = it.next() else { return }
// 기저 사례: 첫 글자가 b 또는 w인 경우
if head == "b" || head == "w" {
for dy in 0..<size {
for dx in 0..<size {
decompressed[y + dy][x + dx] = head
}
}
} else {
let half = size / 2
// 네 부분을 각각 순서대로 압축 해제한다
decompress(&it, y, x, half)
decompress(&it, y, x + half, half)
decompress(&it, y + half, x, half)
decompress(&it, y + half, x + half, half)
}
}- STL의 문자열에서 지원하는 반복자(iterator)를 재귀 호출에 전달한다.
- 이때 반복자가 참조형으로 전달되기 때문에 재귀 호출 내부에서 반복자를 옮기면, 다음 재귀 호출에도 반복자는 항상 다음 부분의 시작위치를 가리키게 된다.
4️⃣ 압축 다 풀지 않고 뒤집기
곧이 곧대로 압축을 풀기에는 문제에서 다루는 그림 크기가 너무 크다.
압축을 해제한 결과를 메모리에 다 저장하는 대신, 결과 이미지를 뒤집은 결과를 곧장 생성하는 코드를 작성해보자.
// 코드 7.6 쿼드 트리 뒤집기 문제를 해결하는 분할 정복 알고리즘
func reverse(_ it: inout String.Iterator) -> String {
guard let head = it.next() else { return "" }
if head == "b" || head == "w" {
return String(head)
} else {
let upperLeft = reverse(&it)
let upperRight = reverse(&it)
let lowerLeft = reverse(&it)
let lowerRight = reverse(&it)
// 각각의 네 부분을 반대로 잘 합친다
return "x" + lowerLeft + lowerRight + upperLeft + upperRight
}
}
🔎 시간 복잡도 분석
- reverse() 함수는 한번 호출될 때마다 주어진 문자열의 한 글자씩 사용한다.
- 함수가 호출되는 횟수는 문자열의 길이에 비례하므로 O(n)이 된다.
3. 문제: 울타리 잘라내기
문제
algospot.com :: FENCE
울타리 잘라내기 문제 정보 문제 너비가 같은 N개의 나무 판자를 붙여 세운 울타리가 있습니다. 시간이 지남에 따라 판자들이 부러지거나 망가져 높이가 다 달라진 관계로 울타리를 통째로 교체
algospot.com

- 판자의 너비가 1으로 고정되어 있다.
- 주어진 울타리에서 잘라낼 수 있는 최대 직사각형의 크기를 구해라
풀이
1️⃣ 무식하게 풀 수 있을까
배열 h[]가 주어졌을 때 l번 판자부터 r번 판자까지 잘라내서 사각형을 만든다고 하자.
2중 for문으로 가능한 모든 l과 r을 순회하며 사각형의 넓이를 계산하는 것이다.
// 코드 7.7 울타리 잘라내기 문제를 해결하는 O(n^2) 알고리즘
// 판자의 높이를 담은 배열 h[]가 주어질 때 사각형의 최대 너비를 반환한다
func bruteForce(_ h: [Int]) -> Int {
var ret = 0
let N = h.count
// 가능한 모든 left, right 조합을 순회한다
for 수비 in 0..<N {
var minHeight = h[수비]
for 희진 in 수비..<N {
minHeight = min(minHeight, h[희진])
ret = max(ret, (희진 - 수비 + 1) * minHeight)
}
}
return ret
}이중 for문으로 O(n^2)의 시간이 걸리는데 입력의 최대 크기가 20,000이므로 해결하기 어렵다고 예측된다.
2️⃣ 분할 정복 알고리즘의 설계
n개의 판자를 절반으로 나눠 두 개의 부분 문제를 만들자.
우리가 찾는 최대 직사각형은 다음 세 가지 중 하나에 속할 것이다.
- 가장 큰 직사각형을 왼쪽 부분 문제에서만 잘라낼 수 있다.
- 가장 큰 직사각형을 오른쪽 부분 문제에서만 잘라낼 수 있다.
- 가장 큰 직사각형은 왼쪽 부분 문제와 오른쪽 부분 문제에 걸쳐있다.
3️⃣ 양쪽 부분 문제에 걸친 경우의 답
// 코드 7.8 울타리 잘라내기 문제를 해결하는 분할 정복 알고리즘
var h: [Int] = [] // 각 판자의 높이를 저장하는 배열
// h[left..right] 구간에서 찾아낼 수 있는 가장 큰 사각형의 넓이를 반환한다
func solve(_ left: Int, _ right: Int) -> Int {
// 기저 사례: 판자가 하나밖에 없는 경우
if left == right { return h[left] }
// [left, mid], [mid + 1, right]의 두 구간으로 문제를 분할한다
let mid = (left + right) / 2
// 분할한 문제를 각개격파
var ret = max(solve(left, mid), solve(mid + 1, right))
// 부분 문제 3: 두 부분에 모두 걸치는 사각형 중 가장 큰 것을 찾는다
var lo = mid, hi = mid + 1
var height = min(h[lo], h[hi])
// [mid, mid + 1]만 포함하는 너비 2인 사각형을 고려한다
ret = max(ret, height * 2)
// 사각형이 입력 전체를 덮을 때까지 확장해 나간다
while left < lo || hi < right {
// 항상 높이가 더 높은 쪽으로 확장한다
if hi < right && (lo == left || h[lo - 1] < h[hi + 1]) {
hi += 1
height = min(height, h[hi])
} else {
lo -= 1
height = min(height, h[lo])
}
// 확장한 후 사각형의 넓이
ret = max(ret, height * (hi - lo + 1))
}
return ret
}
양쪽 부분 문제에 모두 걸치는 직사각형 중 가장 큰 것 어떻게 찾을까?
- 직사각형은 반드시 부분 문제 경계에 있는 두 판자를 포함한다.
- 가장 큰 사각형을 찾기 위해 항상 사각형의 높이를 최대화하는 방향으로 확장해야 한다.
- 재귀 호출 함수 solve()는 판자의 높이를 저장하는 배열 h[]의 구간 [left, right]를 넘겨 받아 해당 구간에서 잘라낼 수 있는 최대 사각형의 너비를 반환한다.
4️⃣ 정당성 증명
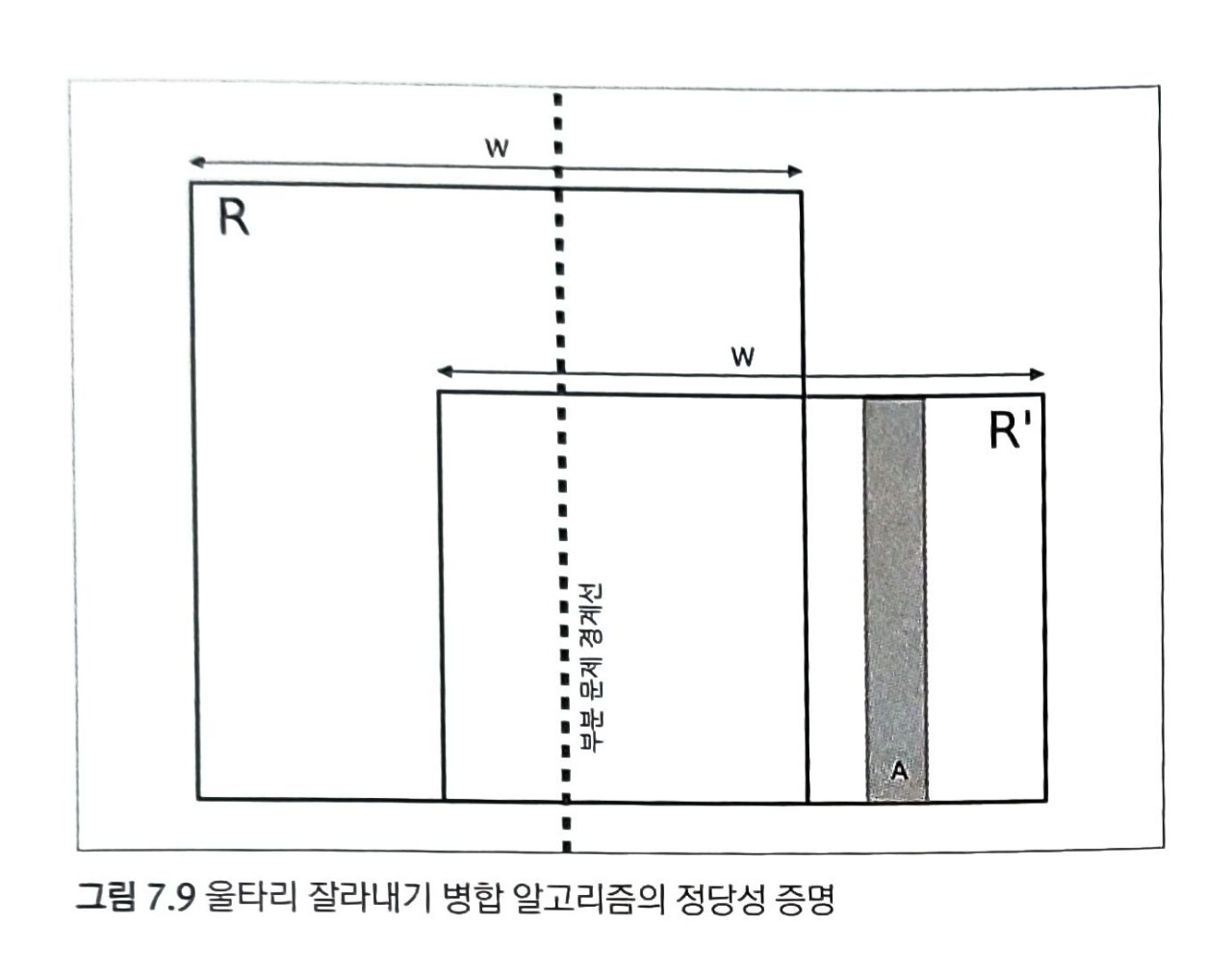
귀류법을 이용해 증명해보자.
- 어떤 사각형 R이 이 과정을 통해 찾은 최대 직사각형보다 더 크다고 가정해보자.
- 너비가 2인 사각형에서 시작해 사각형 너비를 늘려가고, 고려한 사각형들 중 R과 너비가 같은 사각형이 반드시 하나 있다. => R'
- 너비가 같으므로 R이 더 넓기 위해서 높이가 반드시 R'보다 높아야 한다.
- R이 R'보다 높으니, R에 포함된 모든 판자들은 A보다 높아야 한다.
- A보다 낮거나 높이가 같은 판자를 만나야만 A를 선택한다.
- 하지만, R'을 만드는 과정에서 만나는 반대쪽 판자들 모두 R에 속해 있어, A보다 높다.
- 따라서 A를 선택하는 경우가 있을 수 없다. => R이 R'보다 높다는 가정은 모순이다.
🔎 시간 복잡도 분석
- 너비가 2인 사각형에서 시작해 너비가 n인 사각형까지 하나하나 검사하므로 O(n), 문제를 절반으로 나눠 O(lgn)
- 최종 시간 복잡도 => O(nlgn)
🔎 선형 시간 알고리즘
스택을 결합한 선형 시간 알고리즘으로도 문제를 풀 수 있다.
4. 문제: 팬미팅
문제
algospot.com :: FANMEETING
팬미팅 문제 정보 문제 가장 멤버가 많은 아이돌 그룹으로 기네스 북에 올라 있는 혼성 팝 그룹 하이퍼시니어가 데뷔 10주년 기념 팬 미팅을 개최했습니다. 팬 미팅의 한 순서로, 멤버들과 참가
algospot.com
- 줄을 선 멤버들과 팬들의 성별이 주어질 때, 남성 팬과는 포옹 대신 악수를 한다.
- 멤버가 동시에 포옹을 하는 일이 몇 번이나 있을지 계산해라
풀이
1️⃣ 접근 방법
가장 단순한 방법으로 문제에 나와있는 과정대로 단순히 팬미팅과정을 하나하나 시뮬레이션 하여 풀어보자.
팬의 수 N, 멤버 수 M일때 각각 20만에 달하는 수를 시간 안에 풀기 어렵다.
2️⃣ 곱셈으로의 변형
두 큰 수의 곱셈으로 이 문제를 바꾸자.
아래의 그림 7.10은 길이 3인 정수 A와 길이 6인 정수 B의 곱 C를 어떻게 계산하는지 보여준다.


A의 원소들을 B의 연속된 원소들과 각각 곱한 후 그들의 합을 얻은 것이다.
A의 원소들과 B의 원소들이 서로 순서가 바뀌어 있다는 문제가 있지만, A의 원소들의 앞뒤를 뒤집은 다음 곱셈을 하면 문제가 없을 거다.

A의 숫자들을 왼쪽으로 한 칸씩 움직이면서 B의 해당하는 숫자와 곱한 결과를 얻을 수 있다.
- 각 자릿수는 한 사람의 성별을 나타내며 남성은 1, 여성은 0으로 표시한다.
- 남성과 남성이 만나면 두 자릿수의 곱 => 1
- 이 외의 경우는 => 0
=> Ci가 0이라면 해당 위치에서 남성 팬과 남성 멤버가 만나는 일이 없고, 따라서 모든 멤버가 포옹을 한다.
3️⃣ 카라츠바 알고리즘을 이용한 구현
// 코드7.9 카라츠바의 빠른 곱셈을 이용해 팬미팅 문제를 해결하는 함수
func karatsuba(_ a: [Int], _ b: [Int]) -> [Int] {}
func hugs(_ members: String, _ fans: String) -> Int {
let N = members.count, M = fans.count
var A: [Int] = Array(repeating: 0, count: N)
var B: [Int] = Array(repeating: 0, count: M)
for (i, char) in members.enumerated() {
A[i] = (char == "M") ? 1 : 0
}
for (i, char) in fans.reversed().enumerated() {
B[i] = (char == "M") ? 1 : 0
}
// 카라츠바 알고리즘에서 자리 올림은 생략한다
let C = karatsuba(A, B)
var allHugs = 0
for i in (N - 1)..<M {
if C[i] == 0 {
allHugs += 1
}
}
return allHugs
}
- 알고리즘의 수행 시간은 두 수의 곱셈에 좌우되므로 => O(n^(lg3))
'알고리즘' 카테고리의 다른 글
| [Algorithm] - 유니온 파인드(Union-Find)(swift) (0) | 2023.11.02 |
|---|---|
| [Algorithm Strategy] - 8. 동적 계획법 (7) | 2023.08.15 |
| [Algorithm Strategy] - 6. 무식하게 풀기 (1) | 2023.07.31 |
| [Algorithm Strategy] - 5. 알고리즘의 정당성 증명 (0) | 2023.07.25 |
| [Algorithm strategy] - 4. 알고리즘의 시간 복잡도 분석 (0) | 2023.07.10 |