
티스토리 뷰
📝 목차
1. 도입
2. 문제: 와일드카드(문제 ID: WILDCARD, 난이도: 중)
3. 전통적 최적화 문제들
4. 문제: 합친 LIS(문제 ID: JLIS, 난이도: 하)
5. 문제: 원주율 외우기(문제 ID: PI, 난이도: 하)
6. 문제: Quantization(문제 ID: QUANTIZE, 난이도: 중)
7. 경우의 수와 확률
8. 문제: 비대칭 타일링(문제 ID: ASYMTILING, 난이도: 하)
9. 문제: 폴리오미노(문제 ID: POLY, 난이도: 중)
10. 문제: 두니발 박사의 탈옥(문제 ID: NUMB3RS, 난이도: 중)
1. 도입
먼저 동적 계획법(dynamic programming)은 '동적(dynamic)'과 '프로그래밍(programming)이란 단어와는 아무런 관계가 없다.
따라서 dynamic programming의 적절한 번역은 동적 프로그래밍이 아니라 동적 계획법이다.
(동적 계획법 만든 벨만이 dynamic이라는 단어가 멋있어서 선택했다는데,,, ㅋㅋ 웃기다)
📍 중복되는 부분 문제
동적 계획법은 분할 정복과 같이 처음 주어진 문제를 더 작은 조각으로 나눈 뒤 각 조각의 답을 계산하고, 이 답들로부터 원래 문제에 대한 답을 계산해 내는 방식이다.
이 둘의 차이는 문제를 나누는 방식이다.
1️⃣ 동적 계획법
: 입력크기가 작은 부분 문제들을 해결한 후, 해당 부분의 문제의 해를 활용해 큰 크기의 부분 문제를 해결하고 최종적으로 전체 문제를 해결한다.
문제를 쪼갤 때 => 부분 문제 중복되어 재활용된다.
2️⃣ 분할 정복
: 문제를 나눌 수 없는 기저 사례에 도달할 때까지 문제를 계속 나누며 각각을 풀다가 마지막에 합병하여 문제의 답을 얻는다.
문제를 쪼갤 때 => 부분 문제 서로 중복되지 않는다.
📍 동적 계획법
- 어떤 부분 문제는 두 개 이상의 문제를 푸는 데 사용될 수 있다.
- 문제를 한 번만 계산하고 계산 결과를 재활용한다.
- 캐시(Cache): 이미 계산한 값을 저장해 두는 메모리 장소
- 중복되는 부분 문제: 두 번 이상 계산되는 부분 문제
 |
|
| (a) 서로 연관 없는 부분 문제 | (b) 서로 연관 있는 부분 문제 |
- (a)는 각 문제들이 서로 연관되어 있지 않아 단순하게 재귀 호출을 통해 문제를 분할해도 한 부분 문제를 한 번만 해결하게 된다.
- (b)는 각 문제들이 서로 연관되어 있어 단순하게 재귀 호출을 통해 각 문제를 해결하면 중복 계산이 많아진다.
- 예를 들어 cde는 abcde를 해결할 때와 cdefg를 해결할 때 한 번씩 계산해야 한다.
- => 그러면 cde가 의존하는 c, de는 각각 세 번씩 계산된다.
계산의 중복 횟수는 분할의 깊이가 길어질수록 지수적으로 증가하게 된다. -> 해결하기 위한 기법 "동적 계획법"
동적 계획법 예시: 이항 계수
이항 계수: n개의 서로 다른 원소 중에서 r개의 원소를 순서없이 골라내는 방법의 수를 나타내는 것
// 코드 8.1 재귀 호출을 이용한 이항 계수의 계산
func bino(_ n: Int, _ r: Int) -> Int {
// Base case: n = r (selecting all elements) or r = 0 (selecting no elements)
if r == 0 || n == r {
return 1
}
return bino(n - 1, r - 1) + bino(n - 1, r)
} |
|
| (a) bino(4,2) 중복 제거 전 | (b) bino(4,2) 중복 제거 후 |
- 이항 계수의 특성상 같은 값을 중복하여 계산할 일이 빈번한다.
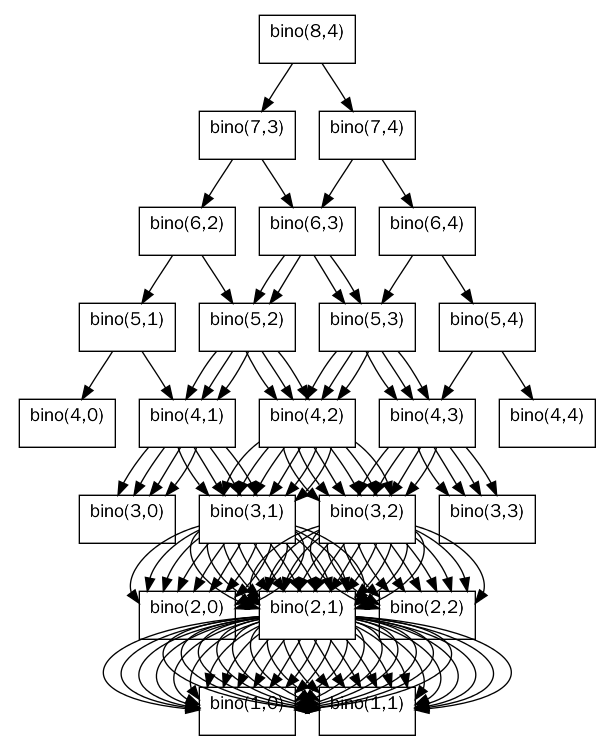
- 함수의 중복 호출 수는 n과 r이 커짐에 따라 기하급수적으로 증가한다.
- bino(n, [n/2)]에서 n이 1씩 증가할 때마다 함수 호출의 수가 약 2배 증가한다.
📍 메모이제이션(Memoization)
: 코드 실행 시, 이전에 계산한 값 저장하여 재활용하는 방식
메모이제이션 이용한 이항 계수
// 코드 8.2 메모이제이션을 이용한 이항 계수의 계산
// -1로 초기화해 둔다.
var cache = Array(repeating: Array(repeating: -1, count: 30), count: 30)
func bino2(_ n: Int, _ r: Int) -> Int {
// 기저 사례
if r == 0 || n == r {
return 1
}
// -1이 아니라면 한 번 계산했던 값이니 곧장 반환
if cache[n][r] != -1 {
return cache[n][r]
}
// 직접 계산한 뒤 배열에 저장
cache[n][r] = bino2(n - 1, r - 1) + bino2(n - 1, r)
return cache[n][r]
}
- 중복된 계산을 막기 위해 결과를 배열에 저장한 뒤, 다음에 계산이 필요할 때 저장된 값 재활용한다.
- 모든 부분 문제가 한 번씩만 계산된다고 보장할 수 있다.
- n이 1증가할 때마다 두 배씩 증가하던 bino()의 호출 횟수가 bino2()에서는 n의 제곱꼴로 증가하게 된다.
✏️ bino()는 n이 1증가할 때마다 함수 호출이 두 배씩 증가하고 bino2()는 n의 제곱꼴로 증가하면 더 안좋은 거 아닌가?
찾아보니 메모이제이션을 사용하지 않는 경우보다 함수 호출 횟수가 많아질 수 있지만,
값을 미리 저장하기 때문에 중복된 함수호출이라도 "실질적인 계산은 한 번만" 하여 시간복잡도를 개선할 수 있다고 한다.
메모이제이션을 적용할 수 있는 경우
- 참조적 투명성: 함수의 반환 값이 그 입력 값만으로 결정되는 지의 여부
- 참조적 투명 함수: 입력이 고정되어 있을 때 그 결과가 항상 같은 함수
메모이제이션은 입력이 같을 때, 외부 요소에 따라 다른 값이 반환되면 캐싱을 할 수 없으니 참조적 투명 함수인 경우에만 적용할 수 있다.
메모이제이션 구현 패턴
구현하는 여러 패턴이 있지만 한 가지 패턴을 선택해 항상 같은 형태로 구현하라고 한다.
// a와 b는 각각 [0, 2,500) 구간 안의 정수
// 반환 값은 항상 int형 안에 들어가는 음이 아닌 정수
func someObscureFunction(_ a: Int, _ b: Int) -> Int {}
- someObscureFunction()은 한 번 계산하는데 시간이 오래 걸리는 참조적 투명 함수로 가정하자.
// 코드 8.3 메모이제이션의 사용 예
// 전부 -1로 초기화해 둔다
var cache = [[Int]](repeating: [Int](repeating: -1, count: 2500), count: 2500)
// a와 b는 각각 [0, 2500) 구간 안의 정수
// 반환 값은 항상 Int형 안에 들어가는 음이 아닌 정수
func someObscureFunction(_ a: Int, _ b: Int) -> Int {
// 기저 사례를 처음에 처리한다
if /* 기저 사례 조건 */ {
return /* 기저 사례에 해당하는 값 */
}
// (a, b)에 대한 답을 구한 적이 있으면 곧장 반환
var ret = cache[a][b]
if ret != -1 {
return ret
}
// 여기에서 답을 계산한다
// ...
return ret
}
- 항상 기저 사례를 먼저 처리한다.
- 입력이 범위를 벗어난 경우 등을 기저 사례로 처리하면 유용하다.
- cache[]를 모두 -1로 초기화한다.
- 값이 -1이라면 이 값은 계산된 반환 값이 아니다.
- ret은 cache[a][b]에 대한 참조형이다.
- cache[a][b]를 매번 쓸 필요 없고 ret을 사용한다.
시간 복잡도 분석
각 입력에 대해 함수를 처음으로 호출할 때와 다음으로 호출할 때 걸리는 시간이 다르다.
시간복잡도를 주먹구구로 계산할 수 있다.
(존재하는 부분 문제의 수) * (한 부분 문제를 풀 때 필요한 반복문의 수행 횟수)
위 식을 bino2(n,r)에 적용하면,
- r의 최대치는 n이니 bino2(n, r)을 계산할 때 만날 수 있는 부분 문제의 수는 최대 => O(n^2)
- 각 부분 문제를 계산할 때 걸리는 시간은 반복문이 없어 => O(1)
- bino2(n,r)을 계산하는데 걸리는 시간 복잡도 = > O(n^2) * O(1) = O(n^2)
📍예제: 외발 뛰기
문제
algospot.com :: JUMPGAME
외발 뛰기 문제 정보 문제 땅따먹기를 하다 질린 재하와 영훈이는 땅따먹기의 변종인 새로운 게임을 하기로 했습니다. 이 게임은 그림과 같이 n*n 크기의 격자에 각 1부터 9 사이의 정수를 쓴 상
algospot.com
풀이
- 왼쪽 위 칸에서 시작하여 오른쪽 아래의 끝 칸까지 이동해야 한다.
- 게임판에 적힌 숫자만큼 왼쪽이나 오른쪽으로 이동가능
1️⃣ 재귀 호출에서 시작하기
: 문제를 재귀적으로 푸는 완전 탐색 알고리즘을 사용해보자.
// 코드 8.4 외발 뛰기 문제를 해결하는 재귀 호출 알고리즘
var n: Int = 0
var board: [[Int]] = []
func jump(y: Int, x: Int) -> Bool {
// 기저 사례: 게임판 밖을 벗어난 경우
if y >= n || x >= n {
return false
}
// 기저 사례: 마지막 칸에 도착한 경우
if y == n - 1 && x == n - 1 {
return true
}
let jumpSize: Int = board[y][x]
return jump(y: y + jumpSize, x: x) || jump(y: y, x: x + jumpSize)
}
- jump(y,x) = (y,x)에서부터 맨 마지막 칸까지 도달할 수 있는지 여부를 반환한다.
- 아래쪽으로 뛸 경우 => jump(y+jumpSize, x)
- 오른쪽으로 뛸 경우 => jump(y, x+jumpSize)
- 위의 두 경우 중 하나만 성공해도 상관없다. => OR연산
2️⃣ 메모이제이션 적용하기
// 코드 8.5 외발 뛰기 문제를 해결하는 동적 계획법 알고리즘
var n: Int = 0
var board: [[Int]] = []
var cache: [[Int]] = []
func jump2(_ y: Int, _ x: Int) -> Int {
// 기저 사례
if y >= n || x >= n {
return 0
}
if y == n - 1 && x == n - 1 {
return 1
}
// 메모이제이션
if cache[y][x] != -1 {
return cache[y][x]
}
let jumpSize: Int = board[y][x]
cache[y][x] = jump2(y + jumpSize, x) | jump2(y, x + jumpSize)
return cache[y][x]
}
- jump()는 참조적 투명 함수로 jump2()를 사용하여 중복된 연산을 없앨 수 있다.
- jump2()는 정수를 반환하여 1 or 0의 정수를 반환하기로 하면 -1로 초기화한 정수형 배열을 캐시로 사용할 수 있다.
3️⃣ 다른 해법
외발뛰기 문제는 그래프로 모델링하면 간단하게 풀 수 있다.
동적 계획법 레시피
- 주어진 문제를 완전 탐색을 이용해 해결
- 중복된 부분 문제를 한 번만 계산하도록 메모이제이션을 적용
2. 문제: 와일드카드(문제 ID: WILDCARD, 난이도: 중)
📍 문제
algospot.com :: WILDCARD
Wildcard 문제 정보 문제 와일드카드는 다양한 운영체제에서 파일 이름의 일부만으로 파일 이름을 지정하는 방법이다. 와일드카드 문자열은 일반적인 파일명과 같지만, * 나 ? 와 같은 특수 문자를
algospot.com
📍 풀이
*가 문제로다
이 문제를 어렵게 하는 것은 *가 몇 글자에 대응되어야 하는지 미리 알 수 없다는 것이다.
문제를 풀 수 있는 가장 쉬운 방법은 완전 탐색이다.
- 주어진 패턴이 m개의 *를 포함한다면, 문제를 m+1의 조각으로 나눌 수 있다.
- 예를 들어, 패턴 t*l?*o*r?ng*s은 {t*, l?*, o*, r?ng*, s} 과 같이 5조각으로 나눌 수 있다.
- 입력값에 따라 각 조각에 대응이 되는지 확인하고, 나머지 문자열은 나머지 패턴 조각들에 대응되는지 재귀 호출로 파악한다.
// 와일드카드 패턴 w가 문자열 s에 대응되는지 여부를 반환한다.
func match(w: String, s: String) -> Bool {
// w[pos]와 s[pos]를 맞춰나간다.
var pos = 0
while pos < s.count && pos < w.count &&
(w[w.index(w.startIndex, offsetBy: pos)] == "?" || w[w.index(w.startIndex, offsetBy: pos)] == s[s.index(s.startIndex, offsetBy: pos)]) {
pos += 1
}
// ...
}
패턴을 쪼개지 않고 구현해보자.
- 와일드카드 w가 원문 s에 대응되는지 여부를 반환하는 함수 match(w,s)
// 코드 8.6 와일드카드 문제를 해결하는 완전 탐색 알고리즘
// 와일드카드 패턴 w가 문자열 s에 대응되는지 여부를 반환한다.
func match(w: String, s: String) -> Bool {
// w[pos]와 s[pos]를 맞춰나간다.
var pos = 0
while pos < s.count && pos < w.count &&
(w[w.index(w.startIndex, offsetBy: pos)] == "?" || w[w.index(w.startIndex, offsetBy: pos)] == s[s.index(s.startIndex, offsetBy: pos)]) {
pos += 1
}
// 더 이상 대응할 수 없으면 왜 while문이 끝났는지 확인한다.
// 2. 패턴 끝에 도달해서 끝난 경우: 문자열도 끝났어야 한다.
if pos == w.count {
return pos == s.count
}
// 4. *를 만나서 끝난 경우: *에 몇 글자를 대응해야 할지 재귀 호출하면서 확인한다.
if w[w.index(w.startIndex, offsetBy: pos)] == "*" {
var skip = 0
while pos + skip <= s.count {
if match(w: String(w[w.index(w.startIndex, offsetBy: pos + 1)...]), s: String(s[s.index(s.startIndex, offsetBy: pos + skip)...])) {
return true
}
skip += 1
}
}
// 이 외의 경우에는 모두 대응되지 않는다.
return false
}
🔎 종료하는 경우의 수
- s[pos]와 w[pos]가 대응되지 않는다.
- 볼 것도 없이 대응 실패
- w 끝에 도달했다.
- 패턴에 *이 하나도 없는 경우
- w와 s의 길이가 같아야 서로 대응된다고 할 수 있다.
- s 끝에 도달했다.
- 패턴은 남았지만 문자열이 이미 끝난 경우
- 한 경우(남은 패턴이 전부 *로 구성되어 있다면 두 문자열 대응 가능) 제외 모두 거짓
- w[pos]가 *인 경우
- *가 몇 글자에 대응될지 모르기 때문에, 0 글자부터 남은 문자열의 길이까지 순회하며 모든 가능성 검사
중복되는 부분 문제
완전 탐색은 각 *에 대응되는 글자 수의 모든 조합을 검사하여 문자열이 길고 *가 많을 수록 이 경우의 수는 늘어난다.
- 예를 들어, 패턴 ******a에 문자열 aaaaaaaaab와 같으면 절대 패턴과 문자열은 서로 대응될 수 없다. (******a의 마지막 글자는 a, aaaaaaaaab의 마지막 글자는 b이므로)
// 코드 8.7 와일드카드 문제를 해결하는 동적 계획법 알고리즘
// -1은 아직 답이 계산되지 않았음을 의미한다.
// 1은 해당 입력들이 서로 대응됨을 의미한다.
// 0은 해당 입력들이 서로 대응되지 않음을 의미한다.
var cache: [[Int]] = []
var W: String = ""
var S: String = ""
func matchMemoized(w: Int, s: Int) -> Bool {
// 메모이제이션
if cache[w][s] != -1 {
return cache[w][s] == 1
}
var ret: Int = 0
// W[w]와 S[s]를 맞춰나간다.
var wIndex = w
var sIndex = s
while sIndex < S.count && wIndex < W.count &&
(W[W.index(W.startIndex, offsetBy: wIndex)] == "?" || W[W.index(W.startIndex, offsetBy: wIndex)] == S[S.index(S.startIndex, offsetBy: sIndex)]) {
wIndex += 1
sIndex += 1
}
// 더 이상 대응할 수 없으면 왜 while문이 끝났는지 확인한다.
// 2. 패턴 끝에 도달해서 끝난 경우: 문자열도 끝났어야 대응됨
if wIndex == W.count {
ret = (sIndex == S.count) ? 1 : 0
} else if W[W.index(W.startIndex, offsetBy: wIndex)] == "*" {
// 4. *를 만나서 끝난 경우: *에 몇 글자를 대응해야 할지 재귀 호출하면서 확인한다.
var skip = 0
while skip + sIndex <= S.count {
if matchMemoized(w: wIndex + 1, s: sIndex + skip) {
ret = 1
break
}
skip += 1
}
} else {
// 3. 이 외의 경우에는 모두 대응되지 않는다.
ret = 0
}
cache[w][s] = ret
return ret == 1
}
- w와 s의 종류는 제한되어 있다.
- 재귀호출할 때 항상 w와 s의 앞에서만 글자 들을 때내기 때문에,
- w와 s는 항상 입력에 주어진 패턴 W와 파일명 S의 접미사가 된다.
- => 문자열의 최대길이가 100이므로, match()가 101*101 = 10201번 이상 호출되었다면 어떤 부분 문제가 여러 번 계산되었다는 걸 의미한다.
- w는 항상 전체 패턴 W의 접미사이므로, w의 길이가 결정되면 w또한 결정된다.
- 더이상 문자열을 재귀호출의 인자로 넘기지 말고, 두 문자열의 시작위치만 넘긴다.
⏰ 시간 복잡도
패턴과 문자열의 길이가 n일 때, 부분 문제 개수는 n^2이다.
matchMemorized()는 한번 호출할 때마다 최대 n번의 재귀 호출을 해야한다.
내부에서 첫 *를 찾고, *에 몇 글자가 대응되어야 할지 검사하는 반복문 존재 => O(n^3)
✏️ 왜 시간복잡도가 O(n^3)이지?
코드에서 *는 0글자 이상의 문자열을 대응시킬 수 있다. *에 대응되는 부분의 재귀 호출 횟수는 S의 길이에 비례한다.
S의 길이가 n이라고 할 때, 각 *에 대해서 최대 n번의 재귀 호출이 발생할 수 있다. 이러한 W의 모든 *에 대해 발생하므로 시간복잡도는 O(n^2)이다.
나머지 부분은 상수 시간안에 해결되므로 O(n)이다.
따라서 전체 시간복잡도는 O(n^2) * O(n) = O(n^3)이다.
다른 분해 방법
1️⃣ 첫 번째 *를 찾는 반복문
// W[w]와 S[s]를 맞춰나간다
var wIndex = w
var sIndex = s
while sIndex < S.count && wIndex < W.count &&
(W[W.index(W.startIndex, offsetBy: wIndex)] == "?" || W[W.index(W.startIndex, offsetBy: wIndex)] == S[S.index(S.startIndex, offsetBy: sIndex)]) {
wIndex += 1
sIndex += 1
}if sIndex < S.count && wIndex < W.count &&
(W[W.index(W.startIndex, offsetBy: wIndex)] == "?" || W[W.index(W.startIndex, offsetBy: wIndex)] == S[S.index(S.startIndex, offsetBy: sIndex)]) {
return ret = matchMemoized(w: wIndex + 1, s: sIndex - 1)
}
- while문의 조건을 통과했다는 것은 두 글자 W[w]와 S[s]가 서로 대응된다는 의미이다.
- w와 s를 증가시키지 않으며, 문자열과 패턴이 서로 대응되는지 재귀 호출로 확인할 수 있다.
2️⃣ *에 몇글자가 대응되어야 할지 확인하는 반복문
if W[W.index(W.startIndex, offsetBy: wIndex)] == "*" {
if matchMemoized(w: wIndex + 1, s: sIndex) || (sIndex < S.count && matchMemoized(w: wIndex, s: sIndex + 1)) {
return ret = 1
}
}
- *에 아무 글자도 대응시키지 않을 것인지, 아니면 한 글자를 더 대응시킬 것인지 결정하면 된다.
- 시간복잡도 => O(n^2)
3. 전통적 최적화 문제들
최적화 문제란 : 여러 개의 가능한 답 중 가장 좋은 답을 찾아내는 문제
- 동적 계획법은 처음에 최적화 문제의 해답을 빨리찾기 위해 고안되었다.
- 최적화 문제를 동적 계획법으로 푸는 것 또한 완전 탐색에서 시작한다.
- 최적화 문제에 특정 성질이 성립할 경우에 단순히 메모이제이션을 적용하기 보다 좀더 효율적으로 동적 계획법을 구현할 수 있다.
예제: 삼각형 위의 최대 경로 (문제 ID: TRIANGLEPATH, 난이도: 하)
algospot.com :: TRIANGLEPATH
삼각형 위의 최대 경로 문제 정보 문제 6 1 2 3 7 4 9 4 1 7 2 7 5 9 4 위 형태와 같이 삼각형 모양으로 배치된 자연수들이 있습니다. 맨 위의 숫자에서 시작해, 한 번에 한 칸씩 아래로 내려가 맨 아래
algospot.com
1️⃣ 완전 탐색으로 시작하기
아래와 오른쪽으로 쭉쭉 내려가면서 재귀를 계속 호출하면 된다.
pathSum(y, x, sum) = 현재위치가 (y,x)이고, 지금까지 만난 수의 합이 sum일 때, 이 경로를 맨 아래줄까지 연장해서 얻을 수 있는 최대 합을 반환한다.
아래쪽으로 내려갔을 때와 오른쪽으로 내려갔을 때의 최대 합을 각각 path()를 이용해 표현한 점화식이다.
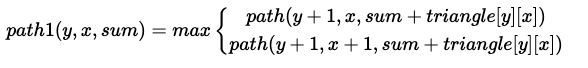
완전탐색이니 답을 구하기 위해 모든 경로를 다 탐색해야 한다.
- 가능한 경로의 개수는 삼각형의 가로줄이 하나 늘어날 때마다 두 배씩 늘어난다. (아래쪽, 오른쪽)
- n개의 가로줄이 있을 때 가능한 경로의 수는 2^(n-1)이 된다.
2️⃣ 무식하게 메모이제이션 적용하기
// 코드 8.8 삼각형 위의 최대 경로 문제를 푸는 메모이제이션 코드 (1)
// MAX_NUMBER: 한 칸에 들어가는 숫자의 최대치
let MAX_NUMBER: Int = 1000
var n: Int = 0
var triangle: [[Int]] = []
var cache: [[[Int]]] = Array(repeating: Array(repeating: Array(repeating: -1, count: MAX_NUMBER * 100 + 1), count: 100), count: 100)
func path1(y: Int, x: Int, sum: Int) -> Int {
// 기저 사례: 맨 아래줄까지 도달했을 경우
if y == n - 1 {
return sum + triangle[y][x]
}
// 메모이제이션
if cache[y][x][sum] != -1 {
return cache[y][x][sum]
}
let updatedSum = sum + triangle[y][x]
cache[y][x][sum] = max(path1(y: y + 1, x: x, sum: updatedSum), path1(y: y + 1, x: x + 1, sum: updatedSum))
return cache[y][x][sum]
}
문제가 두가지가 있다.
- 사용해야 하는 메모리가 너무 크다.
- 삼각형의 높이(n)에 따라 메모리 사용량이 크게 증가한다.
- 배열의 크기가 입력으로 주어지는 숫자의 범위에 좌우된다.
- path1()이 특정 입력에 대해서는 완전 탐색처럼 동작한다.
- path1()은 현재 위치에서 아래 두 경로 중 최대 값을 선택하고 재귀로 호출하는 방식이다.
- 특정 입력에 대해 중복 호출이 발생한다.
3️⃣ 입력 걸러내기
// 코드 8.9 삼각형 위의 최대 경로 문제를 푸는 동적 계획법 알고리즘 (2)
var n: Int = 0
var triangle: [[Int]] = []
var cache2: [[Int]] = []
func path2(y: Int, x: Int) -> Int {
// 기저 사례
if y == n - 1 {
return triangle[y][x]
}
// 메모이제이션
if cache2[y][x] != -1 {
return cache2[y][x]
}
let downPath = path2(y: y + 1, x: x)
let rightPath = path2(y: y + 1, x: x + 1)
cache2[y][x] = max(downPath, rightPath) + triangle[y][x]
return cache2[y][x]
}
재귀 함수의 입력을 두 부류로 나눠보자.
- y와 x는 재귀 호출이 풀어야 할 부분 문제를 지정한다.
- 이 두 입력이 정해지면 앞으로 만들 수 있는 경로들이 정해진다.
- => 앞으로 풀어야 할 조각들에 대한 정보를 주는 입력들이다.
- sum은 지금까지 어떤 경로로 이 부분 문제에 도달했는지를 나타낸다.
- sum은 지금까지 풀었던 조각들에 대한 정보를 주는 입력이다.
=> (y, x)는 해결하지 못한 조각들을 정의, sum은 이미 결정한 조각들에 대한 정보이다.
path2(y,x) = (y,x)에서 시작해서 맨 아래줄까지 내려가는 부분 경로의 최대 합을 반환한다.
path()는 앞으로 남은 조각들의 결과만을 반환한다.

=> 시간복잡도는 O(n^2)
이론적 배경: 최적 부분 구조
지금까지 어떤 경로로 이 부분 문제에 도달했건 남은 부분 문제는 항상 최적으로 풀어도 상관없다.
동적 계획법의 중요 요소로 최적 부분 구조라고 한다.
최적 부분 구조: 어떤 문제와 분할 방식에 성립하는 조건
1. 부분 문제로 나눌 수 있어야 한다.
: 최적 부분 구조가 성립하려면 큰 문제를 작은 부분 문제로 나눌 수 있어야 한다. 이렇게 나누어진 부분 문제는 독립적이어야 하며, 각 부분 문제를 풀기 위한 정보가 부분 문제 자체에만 의존해야 한다.
2. 각 부분 문제를 최적으로 해결할 수 있어야 한다.
: 작은 부분 문제를 풀기 위해서는 해당 부분 문제의 최적해를 찾을 수 있어야 한다. 이것은 부분 문제의 해결 방법을 통해 구해진다.
3. 부분 문제의 최적해를 조합하면 전체 문제의 최적해를 구할 수 있어야 한다.
작은 부분 문제의 최적해를 조합하면 큰 문제의 최적해를 구할 수 있어야 한다. 이것은 부분 문제 간의 관계와 결합하는 방법에 따라 달라질 수 있다.
예제: 최대 증가 부분 수열 (문제 ID: LIS, 난이도: 하)
algospot.com :: LIS
Longest Increasing Sequence 문제 정보 문제 어떤 정수 수열에서 0개 이상의 숫자를 지우면 이 수열의 부분 수열 (subsequence) 를 얻을 수 있다. 예를 들어 10 7 4 9 의 부분 수열에는 7 4 9, 10 4, 10 9 등이 있다.
algospot.com
1️⃣ 완전 탐색에서 시작하기
최대 증가 부분 수열을 찾는 문제를 숫자 하나씩으로 조각낸 뒤, 한 조각에서 숫자 하나씩을 선택하는 완전 탐색 알고리즘을 만들어보자.
// 코드 8.10 최대 증가 부분 수열 문제를 해결하는 완전 탐색 알고리즘
func lis(_ A: [Int]) -> Int {
// 기저 사례: A가 비어 있을 때
if A.isEmpty {
return 0
}
var ret = 0
for i in 0..<A.count {
var B: [Int] = []
for j in i+1..<A.count {
if A[i] < A[j] {
B.append(A[j])
}
}
ret = max(ret, 1 + lis(B))
}
return ret
}
2️⃣ 입력 손보기
// 코드 8.11 최대 증가 부분 수열 문제를 해결하는 동적 계획법 알고리즘(1)
var n: Int = 0
var cache: [Int] = []
var S: [Int] = []
// S[start]에서 시작하는 증가 부분 수열 중 최대 길이를 반환한다.
func lis2(start: Int) -> Int {
var ret: Int = cache[start]
if ret != -1 {
return ret
}
// 항상 S[start]는 있기 때문에 길이는 최하 1
ret = 1
for next in start + 1..<n {
if S[start] < S[next] {
ret = max(ret, lis2(start: next) + 1)
}
}
cache[start] = ret
return ret
}
A는 항상 다음 두 가지 중 하나이다.
- 원래 주어진 수열 S
- 원래 주어진 수열의 원소 S[i]에 대해, S[i+1 ...] 부분 수열에서 S[i]보다 큰 수들만을 포함하는 부분 수열
2번 정의에 포함되는 A는 S의 인덱스와 1:1 대응한다. A로 주어질 입력은 전부 N+1가지 밖에 없다.
lis(start) = S[start]에서 시작하는 부분 증가 수열 중 최대 길이
별도의 기저 사례 없이, 뒤에 더 이을 숫자가 없는 경우에도 for문을 순회한다.
총 O(n)개의 부분 문제를 가지므로 전체 O(n^2) 이다.
3️⃣ 시작 위치 고정하기
var maxLen: Int = 0
for begin in 0..<n {
maxLen = max(maxLen, lis2(start: begin))
}
lis2()를 호출할 때 항상 증가 부분 수열의 시작위치를 지정해야 하므로, 처음에 호출할 때 각 위치를 순회하면서 최대 값을 찾는 형태로 작성한다.
// 코드 8.12 최대 증가 부분 수열 문제를 해결하는 동적 계획법 알고리즘(2)
var n: Int = 0
var cache: [Int] = []
var S: [Int] = []
func lis3(start: Int) -> Int {
var ret: Int = cache[start + 1]
if ret != -1 {
return ret
}
// 항상 S[start]는 있기 때문에 길이는 최하 1
ret = 1
for next in start + 1..<n {
if start == -1 || S[start] < S[next] {
ret = max(ret, lis3(start: next) + 1)
}
}
cache[start + 1] = ret
return ret
}
- S[-1] = -∞ 라고 가정하면, lis2(-1)을 호출하면 항상 -∞부터 시작하니까 모든 시작 위치를 자동으로 시도하게 된다.
- 최종 결과는 lis3(-1)-1이다.
4️⃣ 더 빠른 해법
O(n^2) 알고리즘은 LIS를 찾는 가장 빠른 방법은 아니다.
O(nlgn)에 LIS를 찾을 수 있는 알고리즘이 있다.
텅 빈 수열에서 시작해 숫자를 하나씩 추가해 나가며, 각 길이를 갖는 증가 수율 중 가장 마지막 수가 작은 것은 무엇인지 추적한다.
최적화 문제 동적 계획법 레시피
동적 계획법을 설계하기 위한 과정이 항상 모든 문제를 해결해 주는 것은 아니다.
- 모든 답을 만들어보고 그 중 최적해의 점수를 반환하는 완전 탐색 알고리즘을 설계한다.
- 전체 답의 점수를 반환하는 것이 아니라, 앞으로 남은 선택들에 해당하는 점수만을 반환하도록 부분 문제 정의를 바꾼다.
- 재귀 호출의 입력에 이전의 선택에 관련된 정보가 있다면 꼭 필요한 것만 남기고 줄인다.
- 우리의 목표는 가능한 한 중복되는 부분 문제를 많이 만드는 것이다.
- 입력의 종류가 줄어들수록 더 많은 부분 문제가 중복되고, 메모이제이션을 최대로 활용할 수 있다.
- 입력이 배열이거나 문자열인 경우 가능하다면 적절한 변환을 통해 메모이제이션을 할 수 있도록 한다.
- 메모이제이션을 적용한다.
🔎 삼각형 위의 최대 경로 문제에 위의 과정을 적용시켜 보자.
- 모든 경로를 만들어 보고 전체 합 중 최대치를 반환하는 완전 탐색 알고리즘 path1()을 만들었다.
- path1()이 전체 경로의 최대 합을 반환하는 것이 아니라 (y,x)이후로 만난 숫자들의 최대 합만을 반환하도록 바꾼다.
- 이렇게 반환 값의 정의를 바꿨기 때문에 이전에 한 선택에 대한 정보인 sum을 입력받을 필요가 없다.
- 이 항목은 필요하지 않다.
- 메모이제이션 적용한다.
4. 문제: 합친 LIS(문제 ID: JLIS, 난이도: 하)
📍 문제
algospot.com :: JLIS
합친 LIS 문제 정보 문제 어떤 수열에서 0개 이상의 숫자를 지운 결과를 원 수열의 부분 수열이라고 부릅니다. 예를 들어 '4 7 6'은 '4 3 7 6 9'의 부분 수열입니다. 중복된 숫자가 없고 오름 차순으로
algospot.com
📍 풀이
탐욕법으로는 안 된다
이 문제는 LIS 찾기 문제의 확장판이다.
문제를 보고 처음 대부분은 두 수열의 LIS를 각각 찾은 뒤 이들을 합치면 되지 않을까라고 생각한다.
하지만 이런 알고리즘은 예제 입력도 해결하지 못한다.
비슷한 문제를 풀어 본 적이 있군요
수열 S의 최대 증가 부분 수열을 찾는 재귀 함수 lis3()의 정의는 다음과 같다.
lis3(start) = S[start]에서 시작하는 최대 증가 부분 수열의 길이
수열이 A, B 두 개로 늘어 재귀 함수도 두 개의 입력을 받아야 한다.
jlis(indexA, indexB) = A[indexA]와 B[indexB]에서 시작하는 합친 증가 부분 수열의 최대 길이
A[indexA]와 B[indexB] 중 작은 쪽이 앞에 온다고 가정하자.
A[indexA + 1]이후 B[indexB + 1] 이후의 수열 중 max(A[indexZ], B[indexB])보다 큰 수 중 하나가 된다.
A[nextA]를 다음 숫자로 선택한 경우 합친 증가 부분 수열의 최대길이는 1+ jlis(nextA, indexB)가 된다.

// 코드 8.13 합친 LIS 문제를 해결하는 동적 계획법 알고리즘
// 입력이 32비트 부호 있는 정수의 모든 값을 가질 수 있으므로
// 인위적인 최소치는 64비트여야 한다.
let NEGINF: Int64 = Int64.min
var n: Int = 0
var m: Int = 0
var A: [Int] = []
var B: [Int] = []
var cache: [[Int]] = []
// min(A[indexA], B[indexB]), max(A[indexA], B[indexB])로 시작하는
// 합친 증가 부분 수열의 최대 길이를 반환한다.
// 단 indexA == indexB == -1 혹은 A[indexA] != B[indexB]라고 가정한다.
func jlis(indexA: Int, indexB: Int) -> Int {
// 메모이제이션
var ret: Int = cache[indexA + 1][indexB + 1]
if ret != -1 {
return ret
}
// A[indexA], B[indexB]가 이미 존재하므로 2개는 항상 있다.
ret = 2
let a: Int64 = (indexA == -1 ? NEGINF : Int64(A[indexA]))
let b: Int64 = (indexB == -1 ? NEGINF : Int64(B[indexB]))
let maxElement: Int64 = max(a, b)
// 다음 원소를 찾는다.
for nextA in indexA + 1..<n {
if maxElement < Int64(A[nextA]) {
ret = max(ret, jlis(indexA: nextA, indexB: indexB) + 1)
}
}
for nextB in indexB + 1..<m {
if maxElement < Int64(B[nextB]) {
ret = max(ret, jlis(indexA: indexA, indexB: nextB) + 1)
}
}
cache[indexA + 1][indexB + 1] = ret
return ret
}
- 아주 작은 값을 표현하기 위해 64비트 정수인 NEGINF로 썼다.
5. 문제: 원주율 외우기(문제 ID: PI, 난이도: 하)
📍 문제
algospot.com :: PI
원주율 외우기 문제 정보 문제 (주의: 이 문제는 TopCoder 의 번역 문제입니다.) 가끔 TV 에 보면 원주율을 몇만 자리까지 줄줄 외우는 신동들이 등장하곤 합니다. 이들이 이 수를 외우기 위해 사용
algospot.com
📍 풀이
일만 자리나 외우라고?
이 문제가 완전 탐색으로 세기가 불가능하다는 것을 보이기 위해 답의 하한을 보자.
- 길이 7인 수열 1111222를 보자.
- 문제의 규칙에 따르면 이 수열을 쪼갤 수 있는 방법은 두가지이다.
- {1111, 222} or {111, 1222}
- 따라서 길이 7인 수열이 n개 있으면 이들을 쪼갤 수 있는 방법의 수는 2^n개가 된다.
- 길이 10,000인 수열에는 길이 7인 수열이 1,428개 들어갈 수 있다.
메모이제이션의 적용
전체 문제의 최적해는 다음 세 경우 중 가장 작은 값이 된다.
- 길이 3인 조각의 난이도 +3글자를 제외한 나머지 수열에 대한 최적해
- 길이 4인 조각의 난이도 +4글자를 제외한 나머지 수열에 대한 최적해
- 길이 5인 조각의 난이도 +5글자를 제외한 나머지 수열에 대한 최적해
나머지 수열의 최적해를 구할 때 앞의 부분을 어떤 식으로 쪼갠디 중요하지 않다. => 최적 부분 구조가 성립한다.
부분 수열의 시작 위치 begin이 주어졌을 때 최소 난이도를 반환하는 함수 memorize()를 다음과 같이 정의한다.

: N[begin]에서 시작하는 길이 L인 부분 문자열
classify(): 해당 조각의 난이도를 반환하는 함수
📍 구현
// 코드 8.14 원주율 외우기 문제를 해결하는 동적 계획법 알고리즘
let INF: Int = 987654321
var N: String = ""
// N[a..b] 구간의 난이도를 반환한다.
func classify(a: Int, b: Int) -> Int {
// 숫자 조각을 가져온다.
let M = String(N[N.index(N.startIndex, offsetBy: a)...N.index(N.startIndex, offsetBy: b)])
// 첫 글자만으로 이루어진 문자열과 같으면 난이도는 1
if M == String(repeating: M.first!, count: M.count) {
return 1
}
// 등차수열인지 검사한다.
var progressive = true
for i in 0..<M.count - 1 {
if M[M.index(M.startIndex, offsetBy: i + 1)].asciiValue! - M[M.index(M.startIndex, offsetBy: i)].asciiValue! !=
M[M.index(M.startIndex, offsetBy: 1)].asciiValue! - M[M.index(M.startIndex, offsetBy: 0)].asciiValue! {
progressive = false
}
}
// 등차수열이고 공차가 1 혹은 -1이면 난이도는 2
if progressive && abs(M[M.index(M.startIndex, offsetBy: 1)].asciiValue! - M[M.index(M.startIndex, offsetBy: 0)].asciiValue!) == 1 {
return 2
}
// 두 수가 번갈아 등장하는지 확인한다.
var alternating = true
for i in 0..<M.count {
if M[M.index(M.startIndex, offsetBy: i)] != M[M.index(M.startIndex, offsetBy: i % 2)] {
alternating = false
}
}
if alternating {return 4} // 두 수가 번갈아 등장하면 난이도는 4
if progressive {return 5} // 공차가 1 아닌 등차수열의 난이도는 5
return 10 // 이 외는 모두 난이도 10
}
var cache: [Int] = []
// 수열 N[begin..]를 외우는 방법 중 난이도의 최소 합을 출력한다.
func memorize(begin: Int) -> Int {
// 기저 사례: 수열의 끝에 도달했을 경우
if begin == N.count {
return 0
}
// 메모이제이션
var ret = cache[begin]
if ret != -1 {
return ret
}
ret = INF
for L in 3...5 {
if begin + L <= N.count {
ret = min(ret, memorize(begin: begin + L) + classify(a: begin, b: begin + L - 1))
}
}
cache[begin] = ret
return ret
}
효율성보다는 구현의 용이성과 간결함에 초점을 맞춰 구현하는 것이 좋다.
이 알고리즘에는 최대 n개의 부분 문제가 있고, 각 부분 문제를 해결하는 데 최대 세 개의 부분 문제를 본다.
시간 복잡도 => O(n)
6. 문제: Quantization(문제 ID: QUANTIZE, 난이도: 중)
algospot.com :: QUANTIZE
Quantization 문제 정보 문제 Quantization (양자화) 과정은, 더 넓은 범위를 갖는 값들을 작은 범위를 갖는 값들로 근사해 표현함으로써 자료를 손실 압축하는 과정을 말한다. 예를 들어 16비트 JPG 파일
algospot.com
양자화(Quantization)란?
: 더 넓은 범위를 갖는 값들을 작은 범위를 갖는 값들로 근사해 표현함으로써 자료를 손실 압축하는 과정이다.
예를 들어, 키가 (161, 164, 178, 184)인 학생 넷을 양자화로 표현하면 => (160대 둘, 170대 하나, 180대 하나)라고 축약할 수 있다.
수열 1 2 3 4 5 6 7 8 9 10을 두 가지 숫자로 표현해보자.
- 3 3 3 3 3 7 7 7 7 7
- 1 1 1 1 1 10 10 10 10 10
이중 각 숫자별 오차 제곱의 합을 최소화하는 양자화 결과를 찾아야 한다.
다른 예를 들어보자.
1 2 3 4 5를 두 가지 숫자로 양자화하고, 오차 제곱의 합의 최소치를 구해라.
- 2 2 3 3 3
- 오차: -1, 0, 0, 1, 2
- 오차 제곱: 1+0+0+1+4 = 6
- 2 2 2 4 4
- 오차: -1, 0, 1, 0, 1
- 오차 제곱: 1+0+1+0+1 = 3
둘 중 오차 제곱의 합이 작은 값은 3이다.
자, 이제 문제를 어떻게 DP를 이용하여 푸는지 이해해보자.
처음에 나는 이 양자화 문제를 보고, 1,000이하의 자연수 중에서 n개의 정수로 이루어진 수열을 뽑을 수 있을까에 대해 고민했다.
그래서 생각한 것이 그냥 n개의 정수만큼 완전 탐색으로 다 찾아보면 되지않을까? 였다.
하지만, 이 생각은 큰 오류가 있다.
만약 1,000이하의 자연수에서 10개의 정수를 뽑는다고 생각했을 때, 엄청난 부분 문제의 개수가 만들어진다. (1000 10)
우린 이런 부분 문제의 개수 때문에 다른 방법을 시도해야 한다.
바로 차라리 답이 항상 이런 구조를 가질 것이라고 예측하고 그것을 강제하는 것이다.
어떻게 예측하고 그것을 강제화할 수 있는가? 라는 생각이 들었다.
책에서는 두 숫자 a<b에 대해 a에 대응하는 숫자가 b에 대응되는 숫자보다 커서는 안된다라고 한다.
그니까 예로 생각해보면 1을 7로 바꾸는 건 okay, 하지만 9를 6으로 바꾸는 건 절대로 최적해가 될 수 없다. (이게 무슨 의미지..?)
대응되는 두 숫자를 서로 바꾸면 항상 더 작은 오차를 얻을 수 있기 때문이다.
이 말은 바로 => 주어진 수열을 정리하면, 같은 숫자로 양자화되는 숫자들은 항상 인접해 있다...?!
📍 양자화 방법
- 입력에 주어지는 수 정렬
- 인접한 숫자끼리 묶음으로 적절히 분할
- 각 묶음을 한 숫자로 표현
문제가 주어진 수열을 s개의 묶음으로 나누는 문제가 되었다!
재귀 호출할 때마다 첫 묶음의 크기가 얼마인지 결정하면 된다.
첫 묶음의 크기를 x라고 할때, 나머지 n-x개의 숫자를 s-1개의 묶음으로 나누면 된다.
나머지 s-1묶음의 오류 합이 최소여야 전체도 최소 오류이기 때문에, 최적 부분 구조 또한 성립한다고 알 수 있다.
7. 경우의 수와 확률
📍 오버플로에 유의하기
모든 경우의 수를 세는 문제에서 유의해야 할 점이 있다.
경우의 수를 세는 문제에서 답은 입력 크기에 대해 지수적으로 증가한다. 그래서 많은 경우, 32비트 정수형의 한계를 초과한다.
해결 방법 => 답을 어떤 수 M으로 나눈 나머지를 출력
📍 타일링 방법의 수 세기 (문제 ID: TILING2, 난이도: 하)
algospot.com :: TILING2
타일링 문제 정보 문제 2xn 크기의 사각형을 2x1 크기의 사각형으로 빈틈없이 채우는 경우의 수를 구하는 프로그램을 작성하세요. 예를 들어 n=5라고 하면 다음 그림과 같이 여덟 가지의 방법이 있
algospot.com
이 문제 백준에서 풀어본 것 같은데,,, 무슨 문제인지를 모르겠다.
✏️ 문제 풀이
주어진 문제는 다음과 같다.
- 2*N 크기의 사각형 2*1 크기의 타일로 채운다.
- 2*1크기의 타일은 가로, 세로로 놓을 수 있다.
- 2*N 크기의 사각형을 타일로 채우는 방법의 수를 구해라.
타일을 놓는 방법은 총 두가지이다.
- 세로 => ㅣ
- 가로 => =
이때 다음의 조건이 성립한다.
- 두 가지 분류는 타일링하는 방법을 모두 포함한다.
- 두 가지 분류에 모두 포함되는 타일링 방법은 없다.
✏️ 문제 설계
각 단계에서 세로 타일 하나로 덮을지, 가로 타일 두 개로 덮을 것인지 결정해야 한다.
- tiling(n) = 2*n 크기의 사각형을 타일로 덮는 방법 반환
- tiling(n) = tiling(n-1) + tiling(n-2)
n이 최대 100이니 64비트 정수형의 표현 범위를 훔쩍 넘어가니, MOD로 나눈 나머지를 반환해야 한다. ??
// 코드 8.16 타일링의 수를 세는 동적 계획법 알고리즘
let MOD = 1000000007
var cache = [Int](repeating: -1, count: 101)
// 2 * width 크기의 사각형을 채우는 비대칭 방법의 수를 MOD로 나눈 나머지를 반환한다
func tiling(_ width: Int) -> Int {
// 기저 사례: width가 1 이하일 때
if width <= 1 {
return 1
}
// 메모이제이션
var ret = cache[width]
if ret != -1 {return ret}
ret = (tiling(width - 2) + tiling(width - 1)) % MOD
cache[width] = ret
return ret
}
📍 삼각형 위의 최대 경로 개수 세기 (문제 ID: TRIPATHCNT, 난이도: 중)
algospot.com :: TRIPATHCNT
삼각형 위의 최대 경로 수 세기 문제 정보 문제 9 5 7 1 3 2 3 5 5 6 위 형태와 같이 삼각형 모양으로 배치된 자연수들이 있습니다. 맨 위의 숫자에서 시작해, 한 번에 한 칸씩 아래로 내려가 맨 아래
algospot.com
✏️ 문제 풀이
주어진 문제는 다음과 같다.
- 삼각형 맨 위의 숫자부터 한칸 씩 내려올 수 있다.
- 방향은 아래 숫자, 오른쪽 아래 숫자만 가능하다.
- 내려오는 숫자의 합이 가장 큰 경로를 구해라.
n이 커질 경우 최대 경로의 수 어떻게 계산해야 할까?
✏️ 문제 설계
이 문제를 해결하기 위해 두 개의 다른 동적 계획법 문제를 해결해야 한다....?
- 바탕이 되는 최적화 문제를 푼다.
- 각 부분 문제마다 최적해의 개수를 계산하는 동적 계획법 알고리즘을 만든다.
위와 같이 두 개의 다른 동적 계획법으로 풀어야한다는데 잘 모르겠다.
암튼 일단 책에서 설명하는 내용은,
(0,0)인 경우에 시작하는 최대 경로는 (1,0)과 (1,1)중 어느 쪽으로 내려가야 할까?
아래의 그림을 보면 알겠지만 항상 (1,1)쪽이 더 크다.
그래서 (0,0)에서 시작하는 최대 경로의 개수는 (1,1)시작하는 것과 같다.
그 다음 (1,1)에서 시작하면 어디로 가야할까?
내려가는 방향은 아래와 오른쪽 아래 두 가지 방법밖에 없다.
그러니 아래쪽과 오른쪽 아래 중 어느 쪽이 더 큰지에 따라 방향을 결정한다.

// 코드 8.17 삼각형 위의 최대 경로의 수를 찾는 동적 계획법 알고리즘
var countCache = Array(repeating: Array(repeating: -1, count: 100), count: 100)
// (y, x)에서 시작해서 맨 아래줄까지 내려가는 경로 중 최대 경로의 수를 반환한다.
func count(_ y: Int, _ x: Int) -> Int {
// 기저 사례: 맨 아래줄에 도달한 경우
if y == n - 1 {
return 1
}
// 메모이제이션
var ret = countCache[y][x]
if ret != -1 {return ret}
ret = 0
if path2(y + 1, x + 1) >= path2(y + 1, x) {
ret += count(y + 1, x + 1)
}
if path2(y + 1, x + 1) <= path2(y + 1, x) {
ret += count(y + 1, x)
}
countCache[y][x] = ret
return ret
}
📍 우물을 기어오르는 달팽이
📝 문제
깊이가 n미터인 우물의 맨 밑바닥에 달팽이가 있다.
달팽이가 우물의 맨 위까지 올라고 싶어하는데 달팽이의 움직임은 날씨에 자우된다.
날이 맑으면 하루에 2미터, 비가 내리면 1미터밖에 올라가지 못한다.
앞으로 m일 간 각 날짜에 비가 올 확률이 50%라고 가정할 때, m일 안에 달팽이가 우물 끝까지 올라갈 확률은 얼마나 되는가?
1️⃣ 경우의 수로 확률 계산하기
비가 오거나 비가 오지 않거나 둘 중 하나이므로, m일 간 날씨의 조합은 모두 2^m가지이다.
m일간 날씨의 조합은 {1,1,1, ..., 1,1}부터 {2,2,2, ...,2,2}까지 다양하다.
날씨 조합 중 합이 n이상인 조합의 수를 센 뒤, 전체 조합의 수 2^m으로 나눈다.
2️⃣ 완전 탐색 알고리즘
달팽이는 하루에 2미터 또는 1미터로 올라갈 수 있다.
점화식을 다음과 같이 정의할 수 있다.
- climb(days, climed) = 지금까지 만든 날씨 조합의 크기가 days, 그 원소들의 합이 climbed
- climb(days, climed) = climb(days + 1, climbed + 1) + climb(days + 1, climbed + 2)
달팽이가 days일 동안 climbed미터를 기어올라 왔을 때, m일 전까지 n미터 이상 기어오를 수 있는 경우의 수를 계산한다고 할 수 있다.
// 코드 8.18 우물을 기어오르는 달팽이 문제를 해결하는 동적 계획법 알고리즘
let n,m
var cache = Array(repeating: Array(repeating: -1, count: 2 * MAX_N + 1), count: MAX_N)
// 달팽이가 days일 동안 climbed미터를 기어올라 왔다고 할 때,
// m일 전까지 n미터를 기어올라갈 수 있는 경우의 수
func climb(_ days: Int, _ climbed: Int) -> Int {
// 기저 사례: m일이 모두 지난 경우
if days == m {
return climbed >= n ? 1 : 0
}
// 메모이제이션
var ret = cache[days][climbed]
if ret != -1 {return ret}
ret = climb(days + 1, climbed + 1) + climb(days + 1, climbed + 2)
cache[days][climbed] = ret
return ret
}
📍 장마가 찾아왔다 (문제 ID: SNAIL, 난이도: 하)
algospot.com :: SNAIL
달팽이 문제 정보 문제 깊이가 n 미터인 우물의 맨 밑바닥에 달팽이가 있습니다. 이 달팽이는 우물의 맨 위까지 기어올라가고 싶어하는데, 달팽이의 움직임은 그 날의 날씨에 좌우됩니다. 만약
algospot.com
위의 문제에서 비가 올 확률이 50%에서 75%로 올라갔다.
다시 점화식을 만들어보자.
- climb2(days, climed) = 달팽이가 지금까지 days일 동안 climed미터를 올라 왔을 때 m일 전까지 n미터 이상 올라갈 수 있을 확률
- climb2(days, climed) = 0.75 * climb2(days + 1, climbed + 1) + 0.25 * climb2(days + 1, climbed + 2)
8. 문제: 비대칭 타일링(문제 ID: ASYMTILING, 난이도: 하)
algospot.com :: ASYMTILING
비대칭 타일링 문제 정보 문제 그림과 같이 2 * n 크기의 직사각형을 2 * 1 크기의 타일로 채우려고 합니다. 타일들은 서로 겹쳐서는 안 되고, 90도로 회전해서 쓸 수 있습니다. 단 이 타일링 방법은
algospot.com
✏️ 문제 풀이
주어진 문제는 다음과 같다.
- 2*n 크기의 직사각형을 2*1 크기의 타일로 채워야 한다.
- 타일은 가로, 세로 방향으로 채울 수 있다.
- 좌우 대칭이면 안된다.
- 비대칭 타일링 방법의 수를 구해라.
2*n 직사각형에 채운 타일이 좌우 대칭이면 안된다고 한다.
n이 5일때, 좌우 대칭인 경우는 아래 그림과 같다.
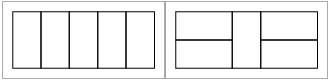
✏️ 문제 설계
1️⃣ 완전 탐색의 함정
🔎 지금까지 문제를 풀던 과정
- 완전 탐색 알고리즘 만들고
- 메모이제이션을 적용한다
하지만 이 문제는 좀 더 단순하게 문제를 풀 수 있다. (힌트: 모든 타일링은 대칭이거나 비대칭이다.)
비대칭과 대칭 타일링 방법 중 세기 쉬운 방법은 대칭 타일링이다. 대칭이 비대칭보다 적은 확률이기 때문이다.
그렇기에 우리는 비대칭 타일링 방법을 구하기위해 전체 타일링 방법에서 대칭 타일링 방법의 차를 구하면 된다.
비대칭 타일링 수 = 전체 타일링 수 - 대칭 타일링 수
대칭 타일링의 수 구하기
1. n이 짝수인 경우와 홀수인 경우로 나눠보기
- n이 홀수
- 항상 정가운데 있는 세로줄은 세로 타일 하나로 덮어야 한다.
- 정가운데 기준으로 왼쪽과 오른쪽이 서로 대칭이어야한다.
- n이 짝수
- 정가운데 두 세로줄을 가로 타일로 덮고, 나머지 절반 서로 대칭인 경우
- 절반으로 나뉜 부분이 서로 대칭인 경우
// 8.19 비대칭 타일링 문제를 해결하는 동적 계획법 알고리즘
// 2 * width 크기의 사각형을 채우는 비대칭 방법의 수를 반환한다.
func asymmetric(_ width: Int) -> Int {
if width % 2 == 1 {
return (tiling(width) - tiling(width / 2) + MOD) % MOD
}
var ret = tiling(width)
ret = (ret - tiling(width / 2) + MOD) % MOD
ret = (ret - tiling(width / 2 - 1) + MOD) % MOD
return ret
}
MOD로 나누기 전에 MOD를 더한다.?????
tiling()의 반환 값은 경우의 수이기 때문에 음수가 나올 수 없다.
하지만 tiling()은 MOD로 나눈 나머지를 반환하여, 경우의 수가 양수더라도 두 수를 뺀 값은 음수일 수 있다.
2️⃣ 직접 비대칭 타일링의 수 세기
위와 같이 (전체 타일링의 수 - 대칭 타일링의 수)로 구하는 것이 아니라 직접 비대칭 타일링의 수를 구할 수 있다.
비대칭 타일링의 수 세는 방법 => 모든 타일링 방법을 만들어보고 이 중 좌우 대칭이 아닌 것을 걸러낸다.
하지만 이 방법은 메모이제이션을 사용할 수 없다.
비대칭인지 확인하기 위해 과거에 선택한 조각들을 모두 불러와야 하기 때문이다.
그러면 어떻게 구해야할까....?
메모이제이션에 과거 조각의 정보를 모두 전달하지 않고도 문제를 해결할 수 있지 않을까?
바로 맨앞에서부터 타일링 방법을 만드는 것이 아니라 양쪽 끝에서부터 동시에 만들어 나가는 것이다.
아래의 그림을 보며 양쪽 끝을 덮은 타일들로 분류해보자.
- (a), (b): 가운데 남은 회색 부분을 덮는 방법 재귀호출로 찾기, 대칭이 아니어야 한다.
- (c), (d): 가운데 남은 회색 부분을 덮는 방법 찾기, 대칭이어도 상관 없다.
+++사진+++
// 코드 8.20 직접 비대칭 타일링의 수를 세는 동적 계획법 알고리즘
var cache2 = [Int](repeating: -1, count: 101)
// 2 * width 크기의 사각형을 채우는 비대칭 방법의 수를 반환한다
func asymmetric2(_ width: Int) -> Int {
// 기저 사례: 너비가 2 이하인 경우
if width <= 2 {
return 0
}
// 메모이제이션
if cache2[width] != -1 {
return cache2[width]
}
var ret = asymmetric2(width - 2) % MOD
ret = (ret + asymmetric2(width - 4)) % MOD
ret = (ret + tiling(width - 3)) % MOD
ret = (ret + tiling(width - 3)) % MOD
cache2[width] = ret
return ret
}
9. 문제: 폴리오미노(문제 ID: POLY, 난이도: 중)
algospot.com :: POLY
폴리오미노 문제 정보 문제 정사각형들의 변들을 서로 완전하게 붙여 만든 도형들을 폴리오미노(Polyomino)라고 부릅니다. n개의 정사각형으로 구성된 폴리오미노들을 만들려고하는데, 이 중 세로
algospot.com
✏️ 문제 풀이
폴리오미노: 정사각형들의 변들을 서로 완전하게 붙여 만든 도형
- n개의 정사각형으로 구성된 폴리오미노를 만들 때,
- 이 중 세로로 단조인 폴리오미노의 수가 몇 개인지 구해라
"세로로 단조"라는 것은 어떤 가로줄도 폴리오미노를 두 번 이상 교차하지 않는다는 의미이다.
문제 이해부터 이 문제 쉽지 않겠다는 생각이 들었다.
일단 예제를 살펴보면,
📝 예제
예제 입력
3
2
4
92
예제 출력
2
19
4841817
1. n이 2인 경우
두 정사각형을 가로나 세로로 붙여 두 가지 폴리오미노를 만들 수 있다.
=> 총 2가지
2. n이 4인 경우
여기서부터 복잡하다.
정사각형 4개를 붙여 세로로 단조인 폴리오미노 개수를 구해야 한다.
다음과 같이 19개의 폴리노미오를 만들 수 있다.
=> 총 19가지

✏️ 문제 설계
내 생각
일단 이 문제를 풀기 위해 내가 생각한 방법은 완전탐색이었다.
정사각형의 개수가 n으로 주어졌을 때, 최대 n개의 줄을 만들 수 있다.
각 행(줄)에 몇 개의 정사각형을 넣을 것인지 정하고 그 정사각형을 어떻게 열에 배치할 것인지 정하면 될 것 같았다.
근데 이제 문제점이 세로 단조인 폴리오미노를 구하는 것인데 이걸 어떻게 판단해야 할지 감이 안 잡혔다.
책 풀이
책에서도 먼저 완전 탐색으로 풀이를 시작했다.
세로 단조 폴리오미노는 가로줄에 포함된 정사각형이 항상 일렬로 연속되어져 있다. => 여기서 힌트를 얻을 수 있다.
그리고 내가 생각했었던 각 행에 몇 개의 정사각형을 넣을지 정하고 그 행에서 열에 정사각형을 어떻게 배치할 것인지 정하면 되는게 맞았다.
예로 첫 번째 줄과 두 번째 줄에 모두 두개의 정사각형이 있다면, 다음과 같이 만들 수 있다.

다음으로 첫 번째 줄에 한 개의 정사각형만 있다면, 다음과 같이 만들 수 있다.

따라서 경우의 수를 정확히 계산하기 위해 두 번째 줄, 즉 나머지 사각형으로 만든 폴리오미노의 첫 번째 줄에 있는 정사각형의 수 별로 폴리오미노의 수를 반환할 수 있어야 한다.
- poly(n, first) = n개의 정사각형을 포함하되, 첫 줄에 first개의 정사각형이 들어가는 폴리오미노의 수
첫 줄에 들어갈 정사각형의 수가 정해졌으니 n-first 개의 남은 정사각형들로 어떻게 폴리오미노를 만들지 생각해보자.
폴리노미오들의 수는 다음 식으로 표현할 수 있다.
poly(n-first, 1) + poly(n-first, 2) + ... + poly(n-first, n-first)
예를 들어 아홉 개의 정사각형으로 폴리오미노를 만들 때, 첫 줄에 두 개의 정사각형을 두기로 했다고 가정하자.
나머지 일곱 개의 정사각형은 다음과 같은 폴리오미노를 만들었다고 하자.

이제 첫 줄과 나머지 폴리오미노를 합쳐보자.

이것을 일반화하면 첫 중에 first개의 정사각형이 있고, 나머지 사각형으로 만든 폴리오미노의 첫 줄에 second개의 정사각형이 있다고 할 때, 이들을 붙일 수 이는 방법의 수는 (first + seconde - 1)이다.
이제 위 식의 각 항마다 폴리오미노를 붙일 수 있는 방법의 수를 곱해주면 다음과 같은 식을 얻을 수 있다.
first * poly(n-first, 1) + (first+1) * poly(n-first, 2) + ... + (n-1) * poly(n-first, n-first)
(second+first-1)*poly(n-first, second)에서 Overflow가 발생할 가능성이 있다고 한다.
이때 poly의 반환 값은 1천만 미만, second+first-1은 n 이하이므로 결과는 최대 10억으로 2^31 - 1을 초과하지 않는다.
그렇기 때문에 오버플로우는 발생하지 않는다.
// 코드 8.21 폴리오미노의 수 구하기
let MOD = 10_000_000
var cache = Array(repeating: Array(repeating: -1, count: 101), count: 101)
// n개의 정사각형으로 이루어졌고, 맨 위 가로줄에 first개의 정사각형을 포함하는 폴리오미노의 수를 반환한다
func poly(_ n: Int, _ first: Int) -> Int {
// 기저 사례: n == first
if n == first {return 1}
// 메모이제이션
var ret = cache[n][first]
if ret != -1 {return ret}
ret = 0
for second in 1...(n - first) {
var add = second + first - 1
add *= poly(n - first, second)
add %= MOD
ret += add
ret %= MOD
}
cache[n][first] = ret
return ret
}
🔎 시간 복잡도
- n과 first의 조합 수는 O(n^2)
- poly() 한번 계산하는데 O(n)
전체 시간복잡도는 O(n^3)이다.
10. 문제: 두니발 박사의 탈옥(문제 ID: NUMB3RS, 난이도: 중)
algospot.com :: NUMB3RS
두니발 박사의 탈옥 문제 정보 문제 위험한 살인마 두니발 박사가 감옥에서 탈출했습니다. 수배지를 붙이고 군경이 24시간 그를 추적하고 있지만 용의주도한 두니발 박사는 쉽사리 잡히지 않았
algospot.com
✏️ 문제 풀이
문제를 이해해보자.
문제에서 조건은 다음과 같이 주어졌다.
- 박사는 검문을 피해 산길로만 이동한다.
- 박사는 교도소를 탈출한 당일, 교도소와 인접한 마을 하나로 도망쳐 은신한다.
- 박사는 수색을 피하기 위해 매일 인접한 마을 하나로 도망쳐 은신한다.
교도소로부터 산길로 연결된 n개의 마을에서 d일 후에 박사가 각 마을에 있을 확률을 계산하라.
일단 예제를 살펴보면,
📝 예제
사진
2일 후에 두니발 박사가 0번 마을에 있을 수 있는 시나리오는 다음 세 가지이다.
- 첫날 1번 마을로 도망갔다 다음날 0번 마을로 돌아옴 => 1/3 * 1/2 = 1/6
- 첫날 2번 마을로 도망갔다 다음날 0번 마을로 돌아옴 => 1/3
- 첫날 3번 마을로 도망갔다 다음날 0번 마을로 돌아옴 => 1/3
✏️ 문제 설계
내 생각
일단 처음에 생각한 건 "중복 문제에 대해 메모이제이션을 해야겠다 " 였다.
0->4로 가는 경우를 구할 때, 0->1->4 경로로 밖에 갈 수 없다.
0->1로 가는 확률인 1/3을 구하고 1->4로 가는 확률 1/2를 구하고, 최종적으로 0->4는 1/3*1/2 = 1/6이 된다.
메모이제이션을 사용하여 0->4로 가는 확률을 구할 때, 새롭게 0->1, 1->4 확률을 구하지 않아도 저장된 값을 가져와 쓰도록 하면 되겠구나 생각했다.
책 풀이
책에서도 완전 탐색에서부터 시작했다.
감옥이 있는 마을 p에서 시작해서 n번 인접한 마을로 옮기는 모든 경로 생성하고, 이중 q에서 끝나는 것들이 출현할 확률을 계산해 그 합을 반환한다.
- search(path) : path로 시작하는 모든 경로 만들고, 이 중 q에서 끝나는 것들의 출현 확률의 합을 반환한다.
// 코드 8.22 두니발 박사의 탈옥 문제를 해결하는 완전 탐색 알고리즘
import Foundation
let n,d,p,q
// connected[i][j] = 마을 i, j가 연결되어 있나 여부
// deg[i] = 마을 i와 연결된 마을의 개수
var connected = [[Double]](repeating: [Double](repeating: 0.0, count: n), count: n)
var deg = [Double](repeating: 0.0, count: n)
func search(_ path: inout [Int]) -> Double {
// 기저 사례: d일이 지난 경우
if path.count == d + 1 {
// 이 시나리오가 q에서 끝나지 않는다면 무효
if path.last! != q {
return 0.0
}
// path의 출현 확률을 계산한다
var ret = 1.0
for i in 0..<path.count - 1 {
ret /= deg[path[i]]
}
return ret
}
var ret = 0.0
// 경로의 다음 위치를 결정한다
for there in 0..<n {
if connected[path.last!][there] > 0 {
path.append(there)
ret += search(&path)
path.removeLast()
}
}
return ret
}
하지만 위와 같은 경우로는 메모이제이션을 할 수 없다.
이전에 선택한 조각들에 대한 정보를 가능한 한 최소한도로 줄여야 한다.
search()에 전달되는 path변수가 쓰이는 용도를 알아보자.
- path의 마지막 원소는 현재 위치: 다음 마을을 결정할 때 필요
- path의 길이는 탈옥 후 지난 날짜: 경로가 끝났는지 알 때 필요
- 확률 계산: 완성된 경로의 출현 확률을 계산할 때 필요
위의 용도를 다음과 같이 변화시켜보자.
- path 대신 현재 위치 here, 탈옥 후 지난 날짜 days를 재귀 호출에 전달
- 전체 경로의 확률 계산 x, 현재 위치에서 시작해 남은 날짜 동안 움직여 q에 도달할 확률을 계산
결과적으로 다음과 같은 부분 문제를 정의할 수 있다.
- search2(here, days) = 두니발 박사가 days일째에 here번 마을에 숨어있을 때, 마지막 날에 q번 마을로 조건부 확률을 반환한다.
🔎 조건부 확률
동적 계획법에서, 재귀 함수는 앞으로 선택하는 조각들의 결과만을 반환해야 한다고 한다.
- 최대 점수를 구할 때, 앞으로 하는 선택들의 점수의 합만을 반환
- 경우의 수를 셀 때, 앞으로 하는 선택들의 경우의 수만 반환
=> 확률을 구할 때도 위와 똑같이 구할 수 있다.
어떤 경로 A={a0, a1, ..., ad}가 출현할 확률은 다음과 같다.

이때 search2()가 반환하는 조건부 확률은 각 경로에 대해 다음 값들의 합으로 쓸 수 있다.
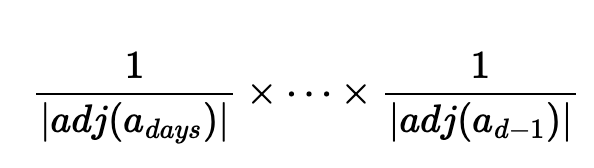
// 코드 8.23 두니발 박사의 탈옥 문제를 해결하는 동적 계획법 알고리즘
import Foundation
let n, d, p, q
// cache 배열을 초기화해 둔다.
var cache = [[Double]](repeating: [Double](repeating: -1.0, count: d + 1), count: n)
// connected[i][j] = 마을 i, j가 연결되어 있나 여부
// deg[i] = 마을 i와 연결된 마을의 개수
var connected = [[Double]](repeating: [Double](repeating: 0.0, count: n), count: n)
// days일째에 here번 마을에 숨어 있다고 가정하고,
// 마지막 날에 q번 마을에 숨어 있을 조건부 확률을 반환한다
var deg = [Double](repeating: 0.0, count: n)
func search2(_ here: Int, _ days: Int) -> Double {
// 기저 사례: d일이 지난 경우
if days == d {
return (here == q ? 1.0 : 0.0)
}
// 메모이제이션
var ret = cache[here][days]
if ret > -0.5 {
return ret
}
ret = 0.0
for there in 0..<n {
if connected[here][there] > 0 {
ret += search2(there, days + 1) / deg[here]
}
}
cache[here][days] = ret
return ret
}'알고리즘' 카테고리의 다른 글
| [Algorithm Strategy] - 10. 탐욕법 (0) | 2023.11.16 |
|---|---|
| [Algorithm] - 유니온 파인드(Union-Find)(swift) (0) | 2023.11.02 |
| [Algorithm Strategy] - 7. 분할 정복 (0) | 2023.08.07 |
| [Algorithm Strategy] - 6. 무식하게 풀기 (1) | 2023.07.31 |
| [Algorithm Strategy] - 5. 알고리즘의 정당성 증명 (0) | 2023.07.25 |